
ファインチューニング、やりたいのに重すぎ問題

「ファインチューニングに挑戦しようと思ったんだけど、GPUメモリが全然足りないって言われて……」
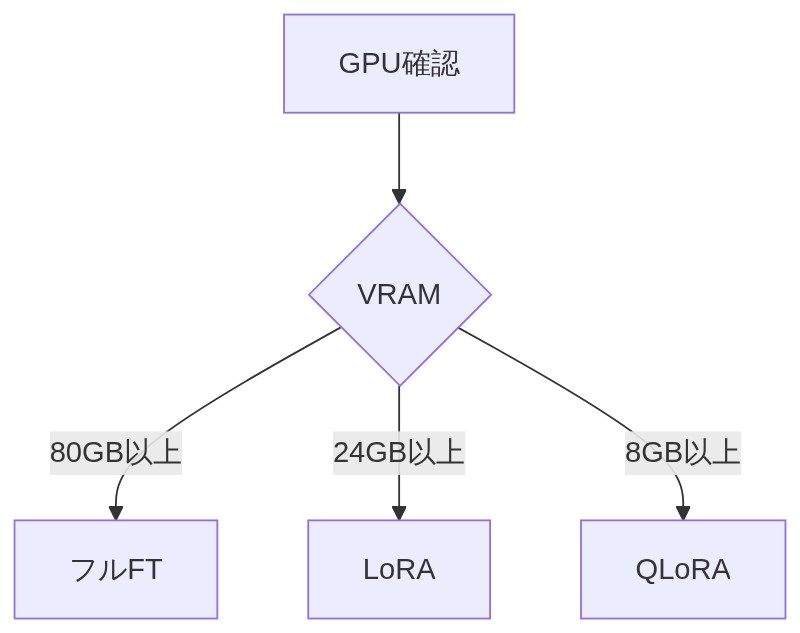
「あるある。7Bのモデルをフルでファインチューニングしようとすると、80GB以上のGPUメモリが必要になることもある。コンシューマGPUじゃ到底無理な世界だよ。」


「80GB!?一般人には不可能じゃん……」
「そこで今日はもっとかしこいやり方、LoRAを紹介するよ。オレが一番おすすめしたい効率化手法だ。」

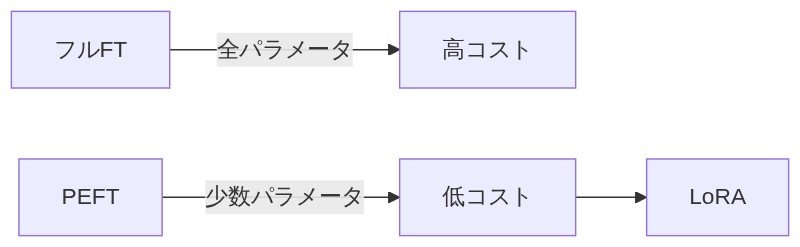
ファインチューニングの「重すぎる」問題
全パラメータ更新の三重苦
AIモデルを特定のタスクに合わせて鍛える「ファインチューニング」。その中でも全パラメータを更新するフルファインチューニングは、とにかくコストが重たい。

「なんでそんなに重いの?」
「7Bモデルっていったら70億個のパラメータがある。それを全部学習中にメモリへ乗せて更新し続けるから、GPUメモリだけで80GB以上が必要になる。しかも時間もかかる、電気代もかかる、保存ファイルもでかい。三重苦だな。」
| コスト項目 | フルFTの問題 |
|---|---|
| GPUメモリ | 7Bモデルで80GB以上必要 |
| 学習時間 | 全パラメータ分の計算が発生 |
| 電力・ストレージ | どちらも膨大 |
「じゃあ一般人はファインチューニングをあきらめるしかないの?」
「あきらめなくていい。PEFT(Parameter-Efficient Fine-Tuning)っていう考え方があってさ、全パラメータじゃなくてごく少数のパラメータだけを効率よく学習する手法の総称なんだ。LoRAはその代表格だよ。」

LoRAの発想 ─ 「全教科復習」から「苦手科目の補習ノート」へ
比喩でつかむLoRAの本質
「LoRAって、具体的にどんな発想なの?」
「試験前に全教科を最初からやり直すのって、めちゃくちゃ大変じゃない?」
「それは絶対無理……」
「でも苦手な科目だけ薄い補習ノートを作って、そこだけ重点的に勉強するなら現実的だろ?」

「それならできる!」
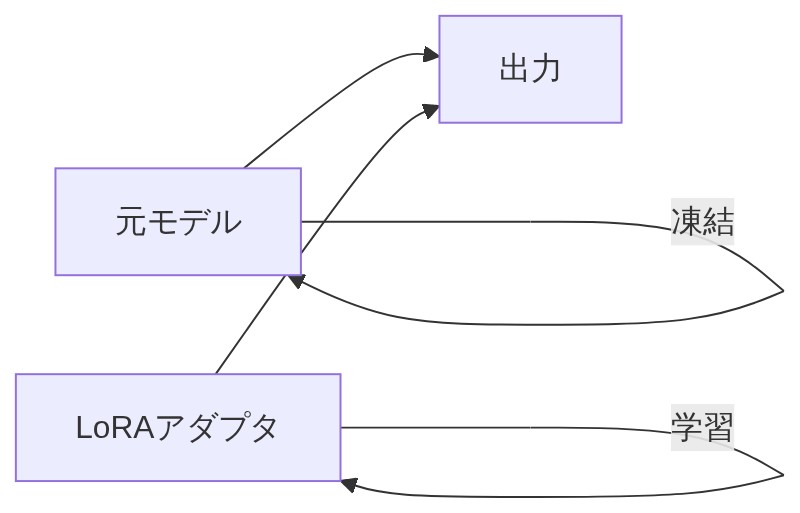
「LoRAはまさにその発想だ。元のモデル(=これまで蓄えた全知識)はそのまま凍結して触らない。そこに小さな”補習ノート”(=LoRAアダプタ)を追加して、その部分だけを学習するんだよ。」
「凍結」って何?アダプタって何?
「凍結するって、元のモデルは学習中に変わらないってこと?」
「そう、元の重みは一切変えない。学習するのはあとからくっつけた小さなアダプタだけだ。だから全体のパラメータのうち0.1%〜1%程度を更新するだけで、フルファインチューニングと同等の性能が出せちゃう。」
「ちょっと待って。1%以下のパラメータ更新で本当に同じ性能が出るの?」
「そこがLoRAの面白いところ。大規模言語モデルの重みの更新って、実は本質的に低次元の情報しか持っていないという特性があるんだ。何十億もあるパラメータ全部を更新しなくても、重要な変化はずっと少ない次元でとらえられる。」
「高次元に見えて、本当に大事な情報はシンプルにまとまってるんだ……!」
「そういうこと。賢い話だろ?」
アダプタはゼロからスタートする
もうひとつ大事なポイント。LoRAのアダプタは学習開始時にほぼゼロに近い値にセットされています。
「なんでゼロ近くからスタートするの?」
「元のモデルが今まで学んできたことを壊さないためだよ。補習ノートを最初から書き散らかしたら、今までの知識が台無しになるだろ?ゼロから始めて、学習しながら少しずつ書き足していくイメージだな。」
「元の知識を守りながら、新しい知識を少しずつ追加していくわけか。」
図解で見るLoRAの仕組み ─ 2つの小さな行列の掛け算
行列AとB、その正体
「LoRAって行列とか出てきて難しそうで……」
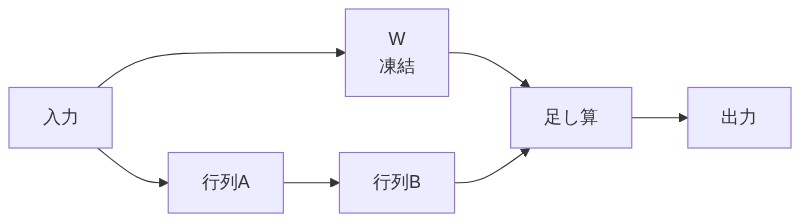
「数式は飛ばして、オレの比喩だけで理解しよう。元のモデルには大きな重み行列Wがある。全知識の塊だと思って。フルFTはこのWを直接書き換える。」
「それが重いんだよね。」
「そう。LoRAはWを触らずに、代わりに行列Aと行列Bという2つのすごく小さな行列を用意する。この2つを掛け合わせたBAを、Wに足し算する形で出力を補正するんだ。」
式にするとこうなります。雰囲気だけで十分です:
出力 = W(元の重み・凍結) + B × A(学習する小さな補正)
「W+BA、つまり元の知識に補習ノートを足し算してるイメージだ。」
「わかった!補習ノートの内容を元の教科書に足してるんだ。」
ランクrって何?なぜ小さくて済むの?
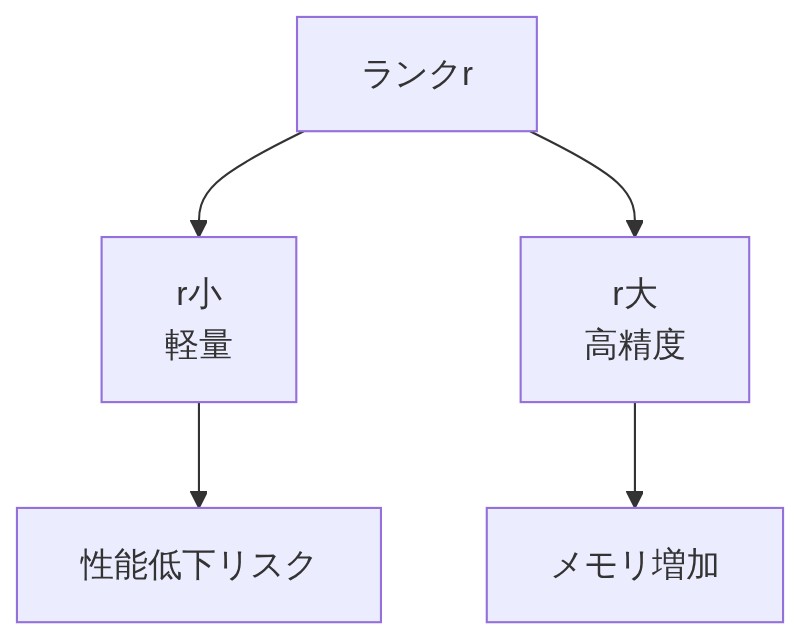
「LoRAの話でよく出てくる『ランクr』って何のこと?」
「rはAとBの行列の太さ・細さを決める数字だよ。元の行列Wが1000×1000の大きさだとしたら、Aは1000×r、Bはr×1000になる。rが小さいほど行列が細くなってパラメータ数が減る。」
「rが小さいほど軽いってこと?」
「そう。でもrが小さすぎると補習ノートが薄すぎて性能が落ちることもある。タスクの難しさや必要な精度に応じて調整していく感じだよ。」
「AとBの2枚の薄い行列に分解するだけで、なんでそんなにパラメータが減るの?」
「たとえばWが1000×1000なら100万パラメータ。でもr=4のとき、Aは1000×4=4000、Bは4×1000=4000、合計8000パラメータだけで済む。元の100万に対して8000だから、ものすごく少ない情報量でWの更新を近似できるわけだ。」
「2枚の薄い板に分解することで、めちゃくちゃ少ない情報量で表現できるんだ!」
QLoRAでさらに軽く ─ 量子化との組み合わせ
QLoRAって何が違うの?
「LoRAだけじゃなくてQLoRAっていうのも聞いたんだけど、何が違うの?」
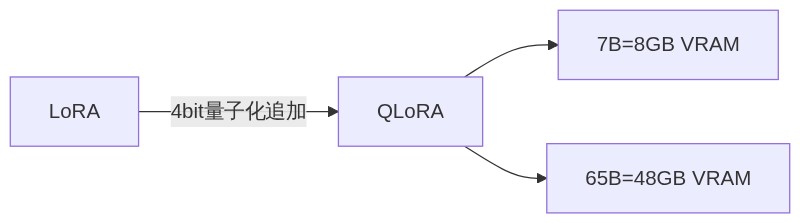
「QLoRAはQuantized LoRAの略で、LoRAに4ビット量子化を組み合わせた手法だよ。」
「量子化って何?」
「モデルの数値の精度をあえて落とすことで、メモリを圧縮する技術だ。普通は32ビットや16ビットの精度で重みを保存してるんだけど、それを4ビットまで減らす。情報は少し粗くなるけど、精度の劣化はごくわずかで済む。」
「どのくらいメモリが減るの?」
「65Bという超巨大なモデルでも48GBのGPUでファインチューニングできるようになる。そして7Bモデルなら8GB VRAMで学習可能になるよ。」
「8GB!?それって家庭用のゲーミングGPUでも動くじゃないですか!」
「そう!RTX 3090や4090(24GB VRAM)なら、QLoRAもLoRAも使えて7B〜13BモデルのファインチューニングがOKになる。個人のGPUでも全然戦えるレベルだよ。」
| LoRA | QLoRA | |
|---|---|---|
| 量子化 | なし | 4ビット量子化あり |
| 必要メモリ | 少ない | さらに少ない |
| 精度 | 高い | ごくわずかな劣化あり |
| 向いてる場面 | VRAMに余裕あり | 個人GPU・省メモリ優先 |
「量子化で精度が落ちるのが心配なんだけど……」
「ごくわずかな劣化で実用上ほぼ問題ないケースが多いよ。使えるGPUの性能と相談しながら選ぶのが現実的だな。」
LoRA・QLoRA・フルFT ─ どれを選べばいい?
自分の環境に合った手法の選び方
「結局どれを使えばいいの?」
「シンプルにまとめるとこう。」
| 手法 | 向いてる人 | GPU目安 |
|---|---|---|
| フルFT | 企業・研究機関レベル | 80GB以上 |
| LoRA | VRAMに余裕のある個人 | 24GB以上(RTX 3090/4090等) |
| QLoRA | 個人ユーザー全般 | 8GB〜24GB |
「個人ユーザーなら基本的にQLoRA一択
参考文献
- https://media.tcdigital.jp/ai-knowledge-flow/articles/lora-peft-cost-benefit/
- https://qiita.com/0h-n0/items/4a87d1161c180e0a6c6a
- https://dataplatform.cloud.ibm.com/docs/content/wsj/analyze-data/fm-tuning-methods-lora.html?context=wx&locale=ja
- https://note.com/agile_chimp9828/n/na1f8dfd557ed
- https://huggingface.co/learn/llm-course/en/chapter11/4
- https://www.emergentmind.com/topics/parameter-efficient-fine-tuning-via-lora
- https://rabiloo.co.jp/blog/llama3-lora-qlora-finetune-guide
- https://renue.co.jp/posts/lora-qlora-peft-finetuning-implementation-guide-2026
- https://qiita.com/y0kud4/items/17b9ebbffa29278bd3dd
- https://www.sciencedirect.com/science/article/abs/pii/S2590291125008113
- https://sakasaai.com/8605-2/

コメント