ファインチューニングとは──料理のレシピで理解するAIの「味付け直し」
「ChatGPTって自分の会社向けにカスタマイズできるって聞いたんだけど、どうすればいいんだろう……」そんな疑問を持ったことはありませんか? その答えのひとつが ファインチューニング です。なんだか難しそうな名前ですが、実は「万能出汁を仕込んで、そこから和食にも洋食にも仕上げていく」料理のプロセスにそっくり。今日は数式ゼロで、このしくみをスッキリ理解していきましょう。

「先生!ChatGPTって、自分の会社専用にカスタマイズできるって聞いたんですけど……どうやるんですか?」
「そのカスタマイズの核心にあるのが ファインチューニング って技術だよ。今日はこれを料理に例えながら、ゼロから丁寧に解説していくな。」

なぜゼロから学習しないのか ─ AIの「学び直し」コスト
「そもそも疑問なんですけど、AIって最初から自分の用途に合わせて作ればよくないですか?なんでわざわざ既存のモデルを使い回すんですか?」
「いい疑問!逆に聞くけど、ラーメン屋を開くとして、スープのダシをゼロから研究するのと、老舗から出汁の素を仕入れてアレンジするの、どっちが早いと思う?」


「……仕入れてアレンジする方が絶対早いですよね。」
「AIも全く同じ話なんだよ。ゼロからモデルを作ろうとすると、既存モデルを使い回す方法に比べて 10〜100倍 ものデータが必要になる。しかも高額なデータ収集のための契約が必要になることも多い。」


「10〜100倍!?それはキツすぎる……」
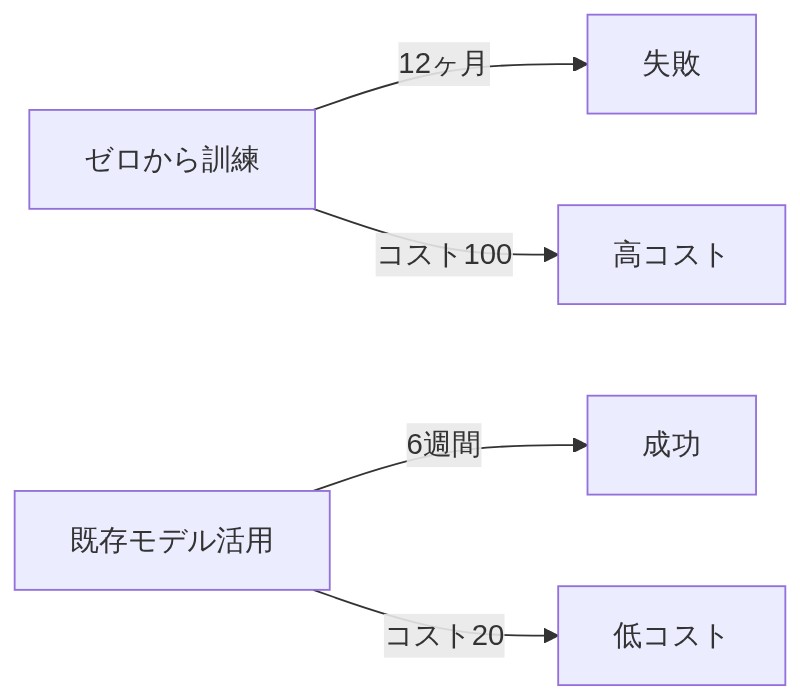
「計算コストもえぐくてな。既存モデルを活用すると計算コストが 80〜90%削減 できるんだ。ゼロからだと100かかるとしたら、使い回せば20くらいで済む計算。」

「じゃあゼロから作ることなんてほとんどないんじゃ……?」
「ほぼそうだね。実際の企業事例でも如実に出てる。2024年のある銀行では、ゼロから開発しようとして 12ヶ月・110万ドル かけたのに失敗したんだ。でも既存モデルの活用に切り替えたら、わずか6週間 でAIの引受ツールを立ち上げることに成功した。」
「えっ、12ヶ月が6週間に!?もう比較にならないですね……」
「ゼロからの訓練が意味を持つのは、自社だけが持つ超希少なデータで莫大な投資を正当化できるケース、ほぼそれだけだよ。」
事前学習 ─ 万能出汁を作る工程
「先生、活用する”既存モデル”って、もともと何を学んでるんですか?」
「そこが大事なポイント!これを説明するのに『万能出汁』の比喩がぴったりなんだよ。」
「万能出汁?」
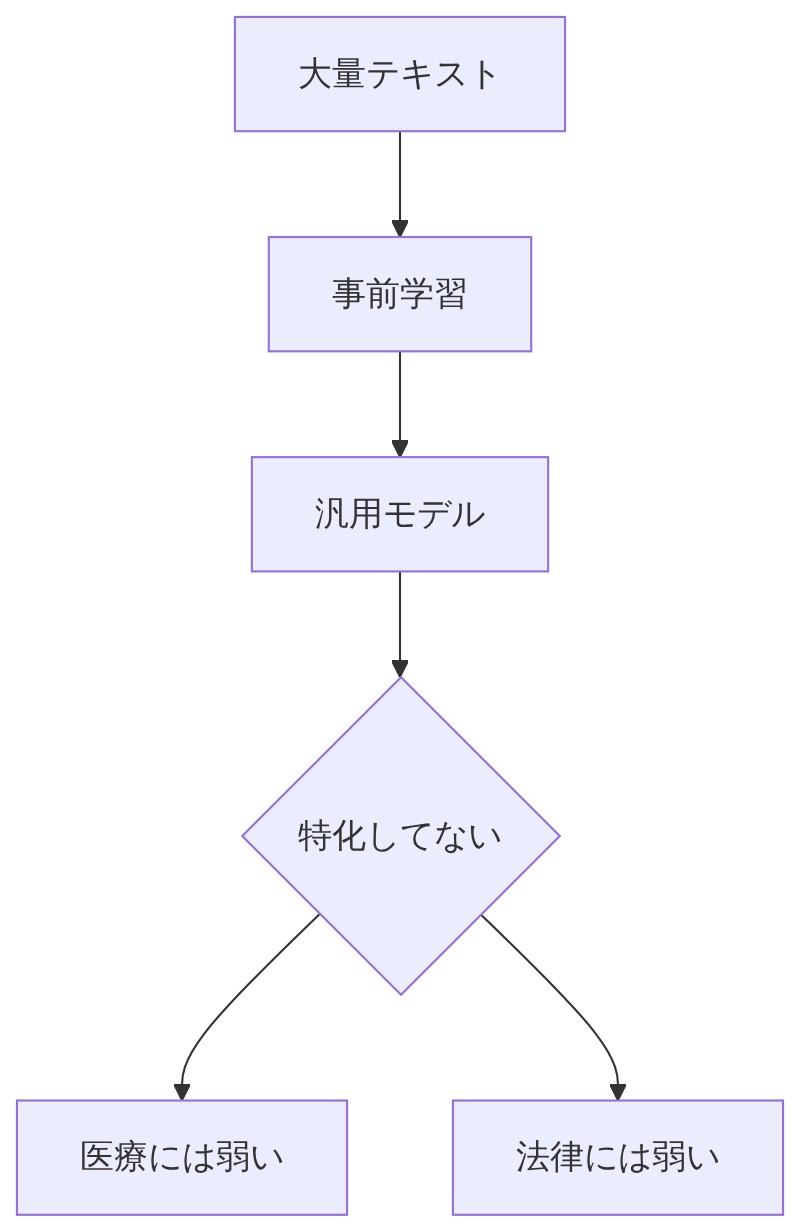
「昆布もかつおもたっぷり使って、和食にも中華にもベースとして使える出汁のことだよ。AIでいう 事前学習(Pretraining) が、まさにこの仕込み工程なんだ。」
「インターネット上の膨大なテキストデータを使って、言語の構造・文法・世界についての知識を丸ごと吸収する工程だよ。GPTやBERTといった大規模言語モデルは、この事前学習によって作られてる。」
「膨大ってどのくらいですか?」
「本・記事・ウェブページ・コードなど、インターネット上のとてつもない量のテキストデータを片っ端から学ぶ規模だよ。その分、時間も計算コストもとんでもなくかかる工程なんだ。」
「それを毎回やり直したら……そりゃコストがえぐいわけだ。」
「そういうこと!だからこそ、この”万能出汁(事前学習済みモデル)”を使い回す発想が生まれた。でも万能出汁のままだと『どの料理にも使えるけど、どの料理にも特化してない』状態なんだよ。」

「特化してないって、たとえばどういうことですか?」
「たとえばChatGPTに最初から『うちの会社の保険商品の専門家として答えて』と言っても、自社商品の細かい知識は持ってないよな?それが『汎用的だけど特定の業務には最適化されてない』ってこと。そこで登場するのがファインチューニングなんだよ。」
ファインチューニング ─ 出汁を和食に仕上げる
「じゃあファインチューニングって、具体的に何をする操作なんですか?」
「万能出汁を手に入れたシェフが、『今日は和食コースを作る』って決めて、醤油・みりん・日本酒で味を整えていく感じ。出汁の旨みはそのまま活かしつつ、和食に合う味に仕上げる工程だよ。」
「AIで言うと、どんな操作をするんですか?」
「事前学習済みモデルに、特定のタスク向けの専用データを追加で学習させることだよ。医療記録・法律文書・自社製品マニュアルなどを使って、モデルをその分野のプロに育て直す感じ。」
「あの……よく聞く『転移学習』とファインチューニングって何が違うんですか?」
「お、鋭い!ここが混乱しやすいポイントなんだよな。まず転移学習から説明するね。」
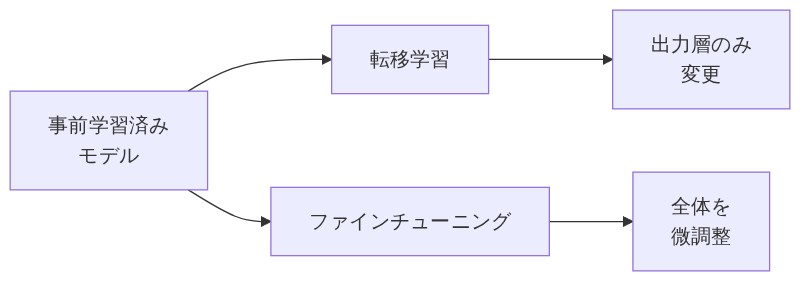
「転移学習は、事前学習モデルのパラメータ(モデルの中に刻み込まれた設定値みたいなもの)をほぼそのまま使って、出力層(最後の部分)だけを新しいタスク用に取り替えるイメージ。」
「出汁で言うと……出汁の中身は変えずに、最後に添える薬味だけ替えるって感じですか?」
「まさにそれ!でファインチューニングはそれより一歩踏み込んで、出力層の付け替えに加えてモデル全体を少しずつ微調整する。出汁を仕込んだ後、全体の濃さや塩加減を改めてチューニングする感じだよ。」
「転移学習が”出口だけ替える”なら、ファインチューニングは”全体を微調整する”んだ!」
「そういうこと。だから必要なデータ量はゼロから学習するより大幅に少なくて済むし、コストも低い。転移学習よりは少し手間がかかる分、特定のタスクへの専門性が高いモデルに仕上がるんだよ。」
「あと、ちょっと聞いていいですか。『パラメータを凍結する』って言葉も見かけるんですけど、これ何ですか?」
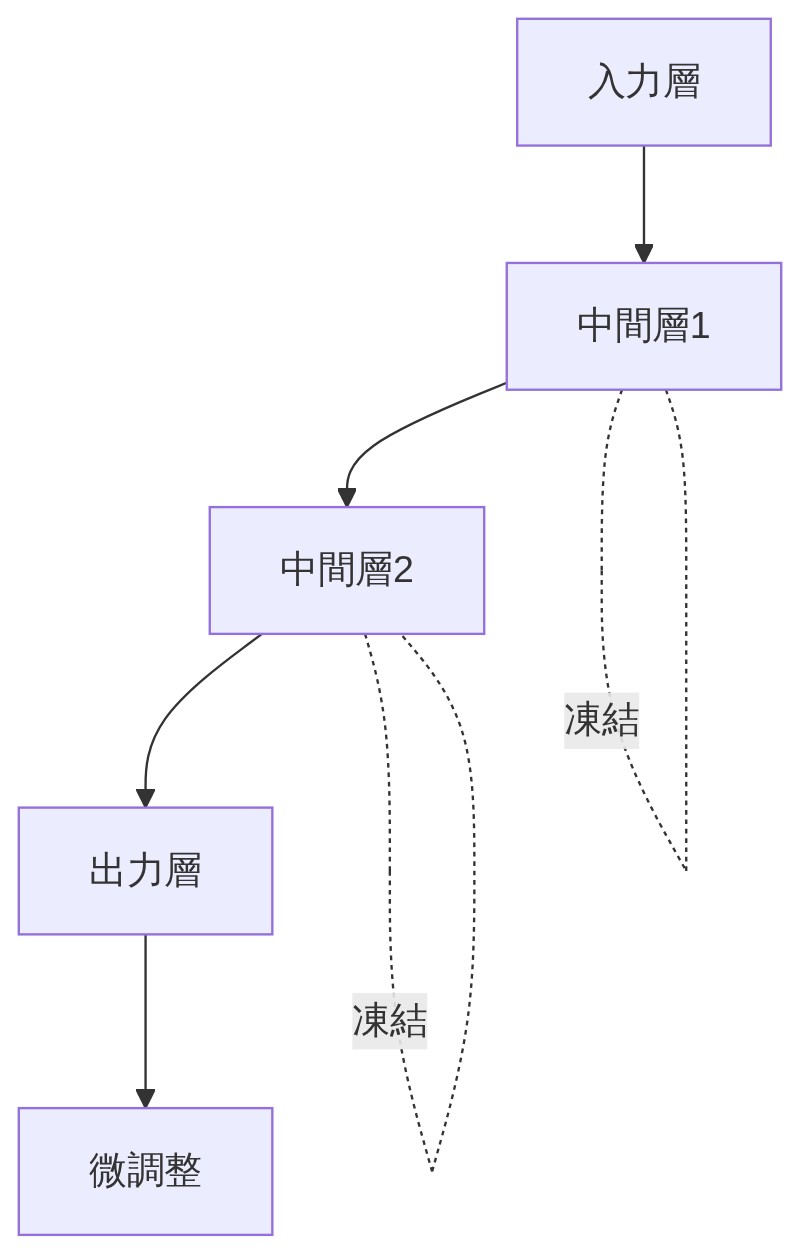
「これも大事なキーワード!モデルの中には”層(レイヤー)”ってものがあって、入力に近い層ほど汎用的な知識(文字の読み方・基本的な文法など)を、出力に近い層ほどタスク固有の知識を扱ってる。」
「凍結するっていうのは、その層のパラメータを変更不可にすること。万能出汁でいえば、出汁の基本的な旨みの部分は触らずに、最終的な味付けの部分だけ調整するイメージだよ。」
「そっちの方がコストも低くなりそう!」
「その通り。どこを凍結してどこを微調整するかは、目的と予算によって変わってくるんだよ。」
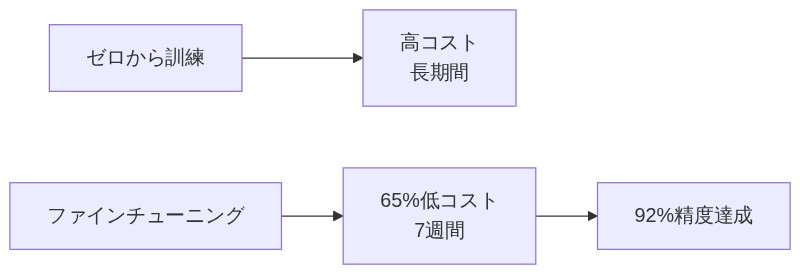
コスト比較 ─ ゼロから vs ファインチューニング
「実際の企業って、ファインチューニングでどのくらい得してるんですか?」
「数字で話そう。SmartDevという企業が転移学習でカスタマーサービスの自動化を実現した事例があるんだけど、7週間で92%の精度を達成して、しかもカスタム開発の見積もりより65%低コストで済んだ。この取り組みは2024年にSao Khue賞も受賞してるよ。」
「65%も安い!しかも7週間ってめちゃくちゃ早いじゃないですか。」
「こういうケースはドキュメント処理やカスタマーサービスみたいな標準的なユースケースで、とくに効果が高いんだよな。」
「逆に、どんな場面ではゼロからの訓練が向いてるんですか?」
「その企業だけが持つ超独自のデータがあって、莫大な追加投資を正当化できる場合だよ。でも正直、最初の選択肢はほぼファインチューニングで問題ない。まずそちらで試して、足りなければ次の手を考えるのが現実的な流れだよ。」
ファインチューニングの注意点と限界
「なんか良いことづくめに聞こえますけど、デメリットや注意点はないんですか?」
「もちろんある。料理の比喩で言うと、万能出汁をいじりすぎると、せっかくの出汁の風味が消えちゃう問題があるんだよ。」
「ひとつ目が 過学習(オーバーフィッティング) のリスク。ファインチューニングをやりすぎると、追加したタスクのデータに過度に適応して、汎用性が失われちゃう。『和食専用に味付けしすぎて、もう洋食には全然使えない出汁』みたいな状態だよ。」
「そしてもうひとつが 壊滅的忘却(catastrophic forgetting) という現象。新しいことを覚えると、事前学習で得た知識が上書きされて失われていくことがあるんだ。」
「壊滅的って、なかなか怖い名前ですね……」
「インパクトある名前だよな(笑)。人間で言うと『新しい仕事の勉強をしていたら、昔の専門知識がだんだん薄れてきた』みたいな感じ。だから学習量・データ量・どの層を調整するかは慎重に選ぶ必要がある。」
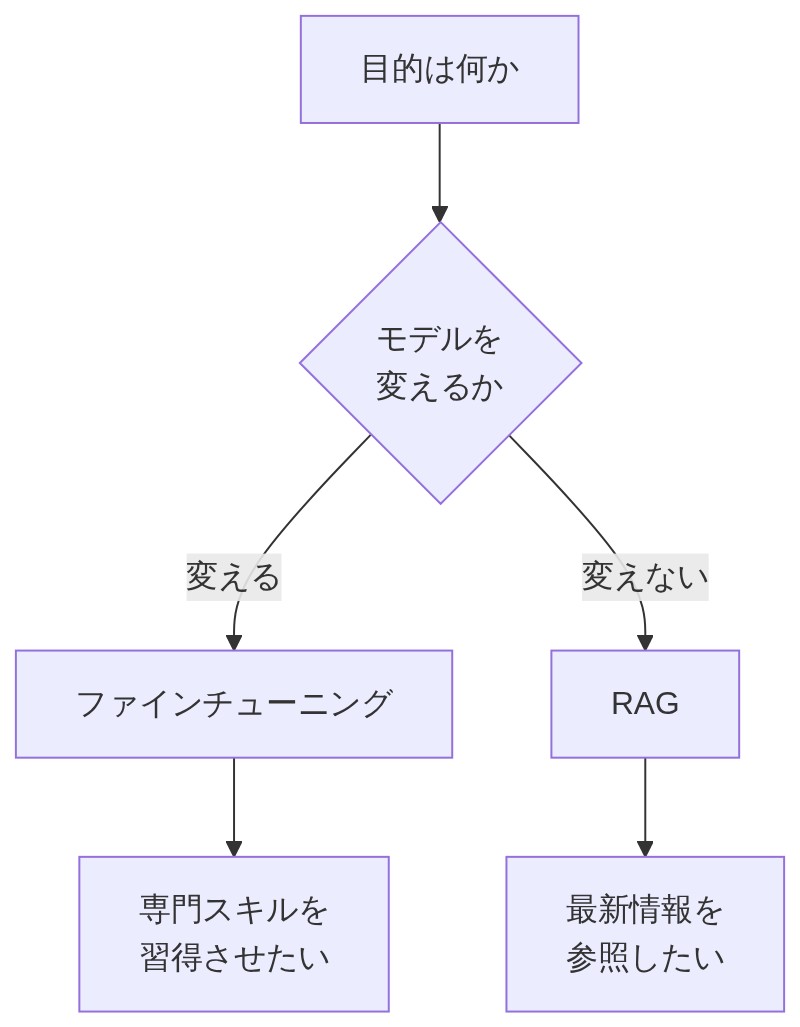
「あと、最近『RAG』って言葉もよく聞くんですけど、ファインチューニングとどう違うんですか?」
「RAGはモデル自体を変えずに、外部のデータベースを参照させる仕組みだよ。料理で例えると……ファインチューニングが”出汁自体をアレンジする”なら、RAGは”料理する直前に新鮮な具材を取り寄せる”イメージかな。」
「ファインチューニングはモデルの中のパラメータを直接変えるけど、RAGはモデルは触らずに外部情報を参照させるだけ。最新情報を使いたい・情報を頻繁に更新したいならRAG、特定の言い回しや専門スキルをモデルに身につけさせたいならファインチューニング、って使い分けが基本だよ。」
「目的によって使い分けるんですね!」
まとめ ─ 万能出汁を活かして自分だけの料理を作ろう
「今日の話を整理してみよう。」
「ファインチューニングって、一言で言うと何ですか?」
「事前学習済みモデルの知識を活かしつつ、少量のデータと低コストで特定のタスクに適応させる技術、かな。万能出汁を捨てずに、自分の料理スタイルに合わせて味を整える作業だよ。計算時間とリソースを大幅に節約しながら、迅速に結果を出せるのが最大の強みだ。」
「ゼロから作らない理由もよくわかりました。10〜100倍のデータ・12ヶ月が6週間に……コストも時間もケタ違いだもんね。」
「そういうこと。今日のポイントをまとめるとこんな感じだよ。」
| ポイント | 内容 |
|---|---|
| 事前学習 | 大量データで汎用知識を習得(万能出汁を仕込む) |
| ファインチューニング | モデル全体を特定タスク向けに微調整(出汁を和食に仕上げる) |
| 転移学習との違い | 転移学習は出力層のみ変更、ファインチューニングはモデル全体を微調整 |
| ゼロからとの差 | 計算コスト80〜90%削減・必要データが大幅に少ない |
| 注意点 | 過学習・壊滅的忘却・RAGとの使い分けを意識する |
「初心者が試すなら、まず何から始めればいいですか?」
「まず既存の事前学習済みモデルを実際に触ってみることだよ。自分の業務でどんなタスクをやらせたいかを明確にして、そのタスク向けのデータを少しずつ準備する。ゼロから始める必要は全くない。万能出汁はもう手元にあるんだから、あとは自分の味付けを楽しむだけだよ!」
「先生、今日の話でファインチューニングがぐっと身近になりました!ありがとうございます。」
「どういたしまして。難しそうに見えても、考え方はシンプルだろ?……なんか話してたらお腹空いてきたな。出汁でも取るか(笑)」

コメント