
「スマホが顔を一瞬で見つける仕組みって、いったい何をしているんだろう?」
数式なしでそこに答えを出すのが、この記事のミッションです。
トカゲ先生とヤモリくんの会話を追いながら、窓拭きという身近な動作を軸に画像認識AIの核心へ迫りましょう。
AIはどうやって画像を「見て」いるのか?





1枚の写真は、縦×横にびっしり並んだ小さな点=ピクセルでできています。そして1つひとつのピクセルには「その点の明るさや色を表す数値」が入っています。人間が見ると「猫」でも、コンピュータが見ると「数字の表」。そのギャップがすべての始まりです。



畳み込み=窓拭き ─ 小さなフィルタで特徴をつかむ

フィルタ(カーネル)って何?
窓拭きのスポンジにあたるのがフィルタ(カーネル)です。
フィルタは画像よりずっと小さい「型紙」のようなもので、「こういうパターンを探してね」という情報が書き込まれています。たとえば──
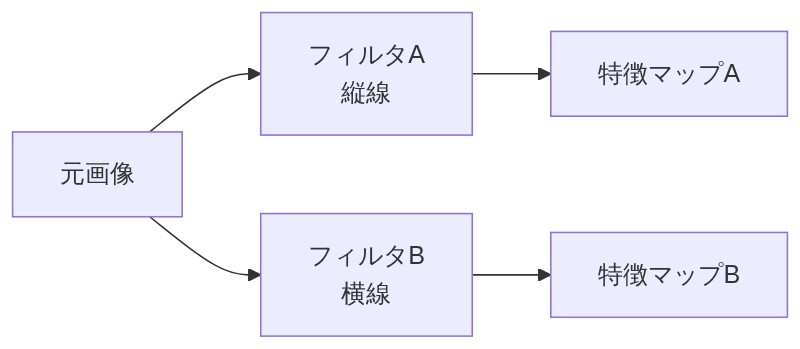
- 縦線を探すフィルタ
- 横線を探すフィルタ
- 斜めのエッジを探すフィルタ

フィルタがスライドする様子をフローで見てみましょう。

フィルタを通した結果=特徴マップ
フィルタが全体を一周すると、「この場所にパターンがあった(値が大きい)」「ここにはなかった(値が小さい)」という反応の地図ができあがります。これを特徴マップ(feature map)と呼びます。
🪟 窓拭き比喩まとめ
窓拭き CNN スポンジ(小さい) フィルタ(カーネル) 窓全体をなでる動き スライド(畳み込み) 汚れがどこにあったかの記録 特徴マップ
プーリング=要点だけメモする ─ 情報を圧縮して強くなる
最大プーリング(MaxPooling)の動き
最も代表的な最大プーリング(MaxPooling)の仕組みはシンプルです。
特徴マップを小さなブロックに区切って、各ブロックの中で一番大きい値だけを残す。

「位置ズレに強くなる」ってどういうこと?

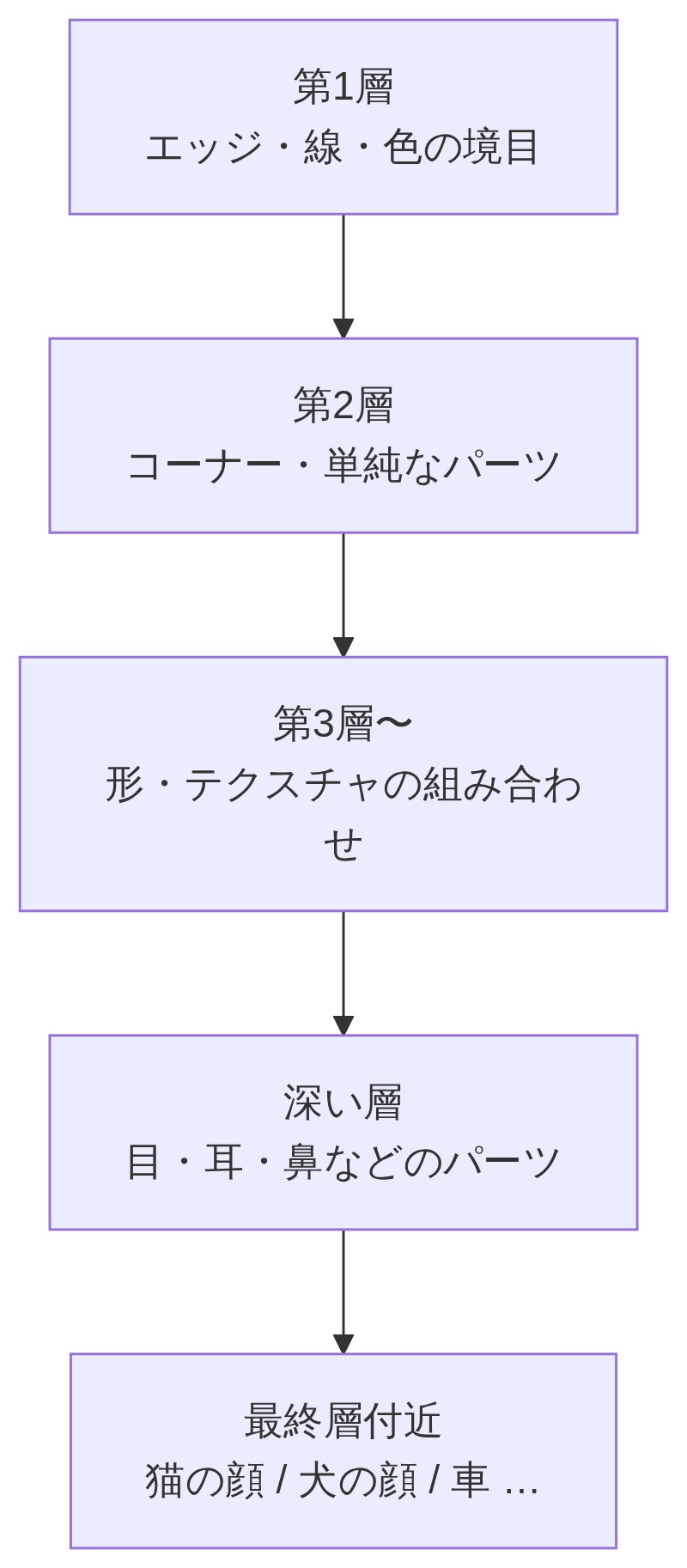
層を重ねると「エッジ→部品→物体」が見えてくる

浅い層:エッジや色の変化を見る
最初の層が学習するのは縦線・横線・色の境目といったシンプルな要素です。猫の写真なら、「どこかに線がある」とわかる段階にすぎません。
深い層:形・テクスチャ・物体を見る
浅い層で見つけた「線」の情報を次の層に渡すと、線と線の組み合わせで形が浮かび上がります。さらに重ねると「耳っぽい形」「目のパーツ」が見え、最終的には「猫の顔!」まで辿り着きます。
全結合層:最後の「判定係」
畳み込みとプーリングを繰り返して集めた特徴を、最後にまとめて答えを出すのが全結合層(Fully Connected Layer)です。
CNNの全体の流れを整理するとこうなります。


CNNが活躍している現場 ─ 自動運転から医療まで
自動運転の「目」になる
自動運転車に搭載されたカメラの映像をリアルタイムでCNNに処理させることで、前方に人がいるか・道路標識は何か・障害物はどこにあるかを素早く把握し、安全な運転制御につなげています。
医療画像診断の「助手」になる
CTスキャンやMRIの画像から腫瘍や病変を自動で検出するAI診断支援にもCNNが活用されています。乳がんや糖尿病網膜症の早期発見への応用も進んでいます。
最新トレンド:Vision Transformer(ViT)との関係
まとめ ─ 「窓拭き」から始まる画像認識の世界
CNNを一言で言うと?
「小さなフィルタ(スポンジ)で画像を窓拭きしながら特徴を取り出し、層を重ねるごとにエッジ→パーツ→物体と認識を深めていく、賢い目のしくみ」
3つのステップがCNNの基本構造です。
| ステップ | 処理内容 | 比喩 |
|---|---|---|
| ① 畳み込み層 | フィルタをスライドして特徴を抽出 | 🪟 窓拭き |
| ② プーリング層 | 代表値を選んで情報を圧縮 | 📝 要点メモ |
| ③ 全結合層 | 特徴をまとめて最終分類 | 🔍 探偵の結論 |
次に学ぶべきステップ
CNNの雰囲気がつかめたら、こんな順番で次へ進んでみましょう。
- 実際にCNNを動かしてみる ─ Pythonを使ったオンライン実行環境で無料で試せます。コードを動かすと「なるほど!」がぐっと増えます。
- 各フィルタが何を学習しているか可視化してみる ─「特徴マップの可視化」で検索すると、フィルタが本当に縦線や曲線を捉えている図が見られて感動します。
- Vision Transformer(ViT)との比較を学ぶ ─ CNNをしっかり理解したあとだと、ViTとの違いがクリアに見えてきます。
参考文献
- https://www.hitachi-solutions-create.co.jp/column/technology/cnn.html
- https://www.veriserve.co.jp/helloqualityworld/media/20251212001/
- https://medium.com/@prajeeshprathap/the-secret-to-understanding-cnns-convolution-feature-maps-pooling-and-fully-connected-layers-97055431a847
- https://www.baeldung.com/cs/cnn-feature-map
- https://encord.com/blog/convolutional-neural-networks-explained/
- https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks/
- https://www.upgrad.com/blog/basic-cnn-architecture/
- https://optage.co.jp/business/contents/article/convolutional-neural-network.html
- https://ai-market.jp/technology/cnn/
- https://yopaz.jp/tech-blog/2025-image-recognition-trends/
- https://en.wikipedia.org/wiki/Convolutional_neural_network

コメント