RAGって何?──AIに「カンペ」を渡す技術を5分で理解する
はじめに

「AIって嘘をつくって本当ですか?」
「本当だよ。でもその理由と、対策技術を理解すれば、AIと上手に付き合えるようになる。今日話すRAGっていう技術を知れば、かなりクリアになるはずだ。」


「ラグ……?なんですかそれ?」
「一言で言うなら、AIにカンペを渡す技術だ。テスト前に教科書を丸暗記させるんじゃなくて、テスト中に参考資料をリアルタイムで見せてあげる、そんなイメージ。今日はこの比喩を軸に、5分で全体像をつかんでいこう!」
AIはなぜ「嘘」をつくのか ─ ハルシネーション問題
「そもそも、なんでAIって嘘をつくんですか?賢そうに見えるのに…」
「LLM(大規模言語モデル)はざっくり言うと、大量のテキストで事前学習されたモデルだ。その学習データをもとに回答を組み立てる。問題はここにある。」


「どんな問題ですか?」
「学習データに含まれていない情報には、そもそも答えを持っていないんだ。昨日起きた出来事とか、君の会社の社内マニュアルとか。そういう情報は学習に入っていないから、AIは本来『知らない』はずなんだよ。」
「でも答えてくれますよね?」
「それが問題!知らないのに、知っているかのようにもっともらしい嘘を生成しちゃうんだ。これがハルシネーション、日本語に訳すと『幻覚』だな。」

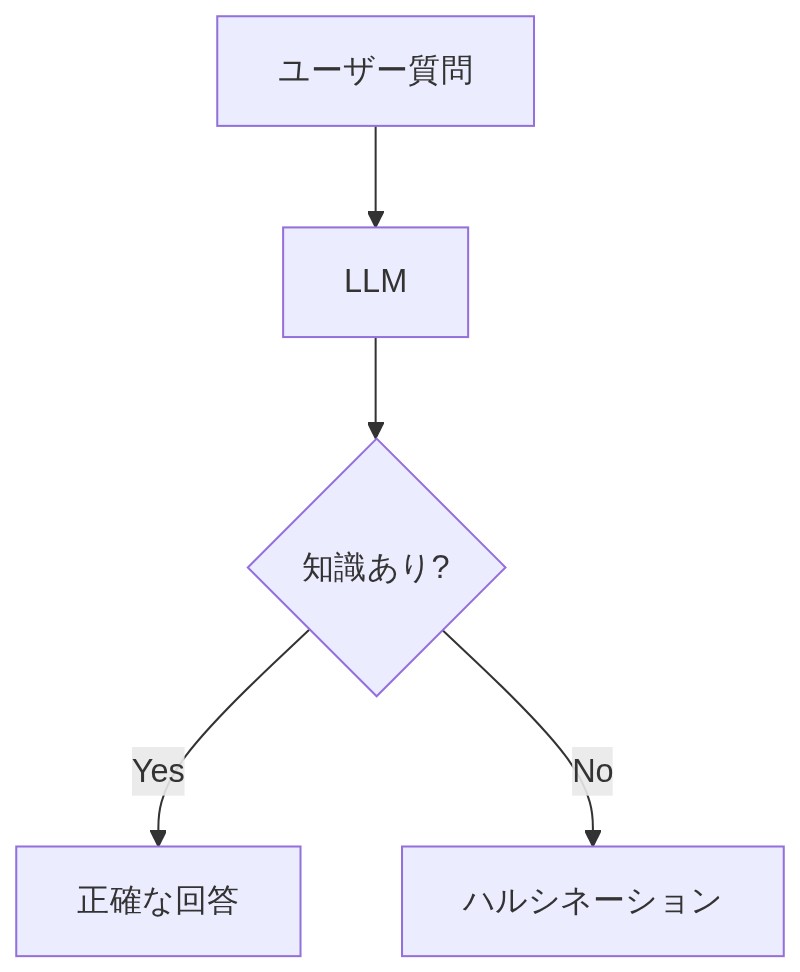
「怖い…。対策はないんですか?」
「プロンプト(AIへの指示文)の中で、『参照データに答えがない場合は推測せずに「わかりません」と答えてください』と指示する手法はある。ただこれだけだと根本解決じゃない。最新情報や専門情報の不足という問題は残ったままだからな。だからRAGが登場するわけだ。」

RAGの基本 ─ テスト中に「カンペ」を見せる仕組み
「じゃあRAGって何をしているんですか?」
「まず正式名称から整理しよう。RAG = Retrieval-Augmented Generation、直訳すると『検索で強化された生成』だ。」
「言葉だとピンとこない…」
「だよな。だからカンペで考えよう。」
「カンペなしのAI」vs「カンペありのAI」
想像してみてほしい。
- 従来のLLM = 何も持ち込めない受験生。事前に頭に詰め込んだ知識だけで全問に答えなければならない。
- RAG付きLLM = 公式の参考資料を持ち込んでいい試験。その場で正確な情報を確認してから答えられる。
「RAGはRetriever(検索係)とGenerator(回答係)という2つのコンポーネントでできている。Retrieverが外部の信頼できるデータから関連情報を引っ張ってきて、Generator、つまりLLMがその情報をもとに文章を生成する。分業制だな。」

「検索してから生成するんですね!」
「そう!その順番が大事。先に調べる、それから答える。これがRAGの本質だ。」
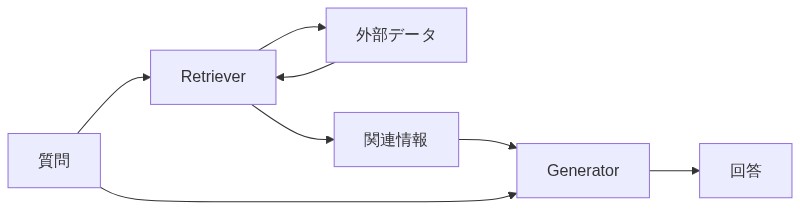
「従来のLLMとの一番の違いは何ですか?」
「従来型は学習済みの知識だけで汎用的に答える。RAGは外部データを動的に参照できるから、最新情報や専門的な社内情報にも柔軟に対応できる。これが最大の違いだ。」
テキストを数字に変える ─ エンベディングとベクトル検索
「カンペを渡すのはわかったんですが、大量の文書の中からどうやって『関係ある情報』を素早く見つけるんですか?」
「いい質問。そこで登場するのがエンベディング(埋め込み)だ。」
「エンベディング?」
「テキストを数字のリスト(ベクトル)に変換する技術のことだ。『犬』という単語も『猫』という単語も、コンピュータには数字の羅列として扱われる。そしてその数字の『方向』が近いほど、意味が似ていると判断できる仕組みなんだよ。」
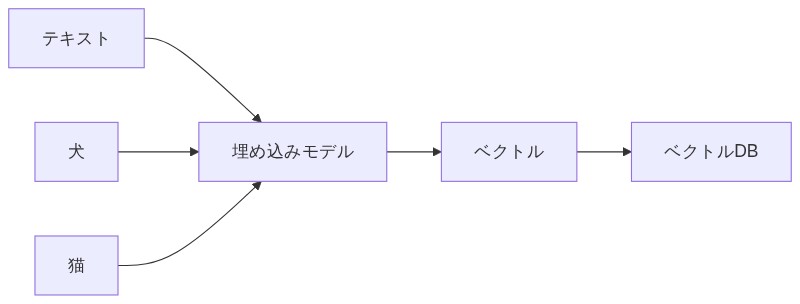
「数字で意味の近さがわかるんですか!?」
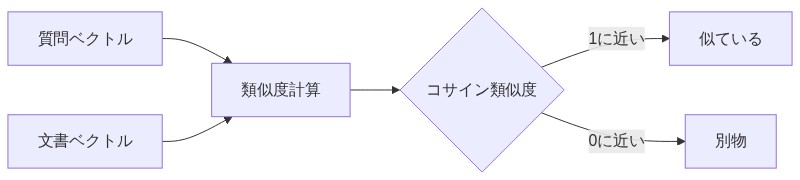
「そう。その近さを測る指標がコサイン類似度だ。2つのベクトルの向きがどれだけ近いかを見る数値で、−1〜1の範囲で表される。1に近いほど『意味が似ている』ということだ。」
「コサイン……なんか数学っぽくて怖いです」
「イメージだけつかめば大丈夫。2本の矢印がほぼ同じ方向を向いていたら『似ている』、全然違う方向だったら『別物』、それだけだ。」
「そのエンベディングに変換した文書をまとめて保管しておく場所がベクトルデータベース。高次元の空間にたくさんの文書ベクトルが格納されていて、質問ベクトルと意味的に近い文書を高速かつ正確に探し出せる。」
「文書をあらかじめ数字に変換しておくから、検索が速いんですね!」
「完璧な理解だ!」
文書をどう切る?─ チャンク分割の考え方
「じゃあ文書をそのままベクトルデータベースに入れればいいですよね?」
「甘い!そこに落とし穴がある。ドキュメントをそのまま1つのベクトルにすると、検索がうまくいかないんだ。」
「なんでですか?」
「100ページの本を1行の要約にしたら、どの部分の話かわからなくなるだろ?それと同じ。だから文書を小さなかたまり、チャンクに分割する必要がある。それぞれのチャンクが意味的に関連するコンテンツを含むように切り出すわけだ。」
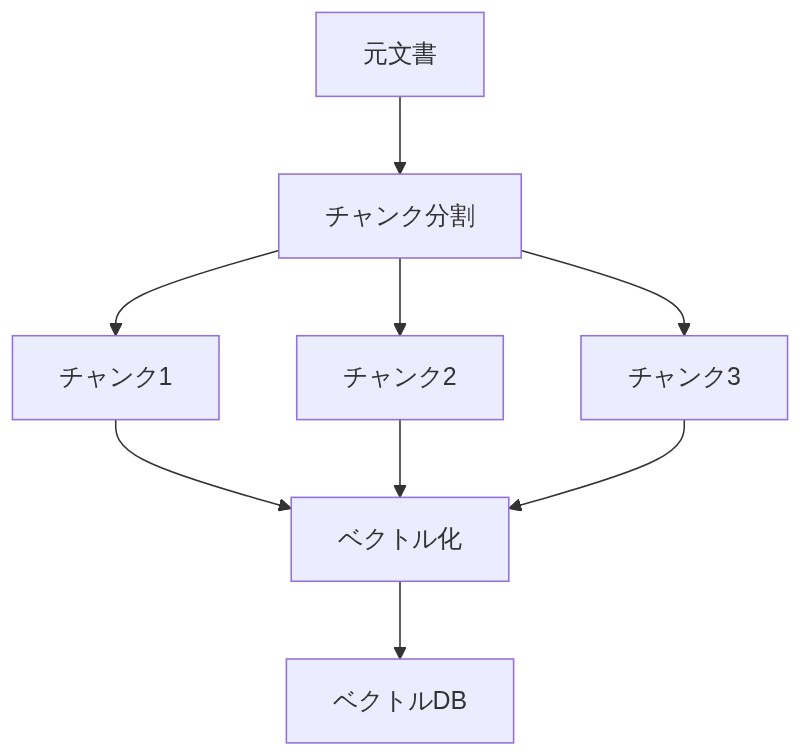
「チャンクってどのくらいの大きさにすればいいんですか?」
「これが結構難しくてな。チャンクが大きすぎると関係ない情報が混ざり込んで精度が落ちる。逆に小さすぎると文脈が失われて、意味がわからない断片になっちゃう。」
「どっちもダメなんですね…」
「そう。チャンキングは単なる『文章を切る』作業じゃなくて、検索精度・文脈の保持・コスト・処理速度を全部コントロールする重要な設計工程なんだよ。適切なサイズ設定がRAGの精度を大きく左右する。」
「カンペの切り方が雑だと、いくら渡しても役に立たないってことですね…」
「その通り(笑)。」
RAGの全体フロー ─ 質問から回答ができるまで

「パーツがだいぶわかってきました!全体の流れをつなげて教えてもらえますか?」
「よし、一気に見ていこう。RAGのパイプラインは大きく検索フェーズと生成フェーズの2つだ。」
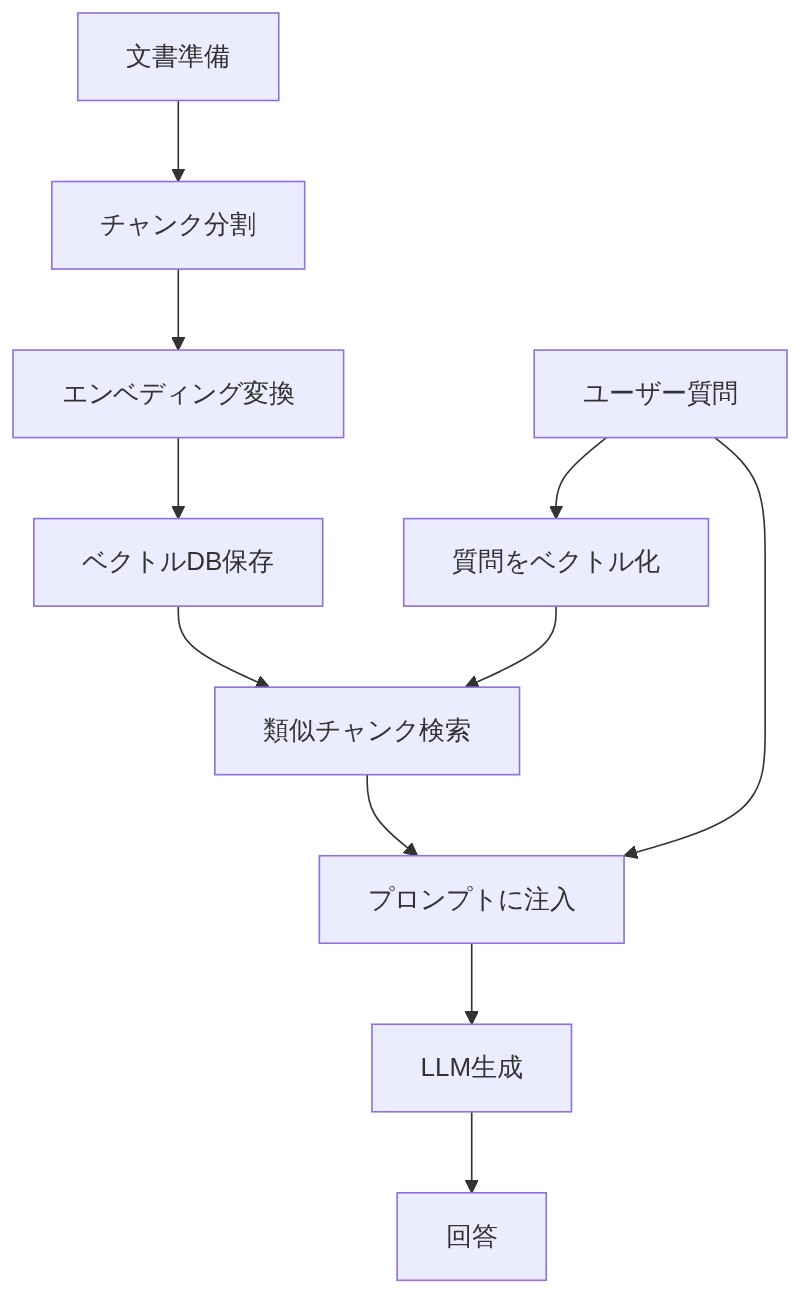
ステップ①:文書をカンペとして準備する
「まず事前準備として、使いたい文書をチャンクに分割して、それぞれをエンベディングに変換し、ベクトルデータベースに保存しておく。カンペを作り置きしておく工程だな。」
ステップ②:質問をベクトルに変換して検索する(検索フェーズ)
「ユーザーが質問を送ってきたら、その質問文も同じようにエンベディングに変換する。」
「質問も数字にするんですね。」
「そう。そのベクトルをベクトルDBに照合して、コサイン類似度が高い、つまり意味的に近い文書チャンクを取り出す。これが検索フェーズだ。」
ステップ③:検索結果をプロンプトに注入する
「取り出した文書チャンクをLLMへの指示(プロンプト)の中に一緒に渡す。『この資料を参考にして答えてください』って感じでカンペを添付するわけだ。」
「カンペごとAIに渡すんですね!」
ステップ④:LLMが回答を生成する(生成フェーズ)
「LLMはそのカンペ(検索結果)を見ながら、ユーザーの質問に対する回答を生成する。これで最新情報や専門的な社内情報に基づいた正確な回答ができるようになるわけだ。」

もっと精度を上げたい ─ ハイブリッド検索とリランキング
「ベクトル検索だけじゃ足りないこともありますか?」
「あるある。たとえば固有名詞や専門用語は、意味の近さよりもキーワードの一致で探した方がいい場合もある。そこで登場するのがハイブリッド検索。キーワード検索とベクトル検索(セマンティック検索)を組み合わせて検索精度を底上げする手法だ。」
「いいとこ取りですね!」
「さらに検索で引っかかった結果を精査するリランカー(re-ranker)という仕組みもある。検索結果にスコアをつけて、最も関連性の高いものを上位に並べ替えてからLLMに渡す。カンペをより使いやすい順番に整理してあげる係だな。」
「ハイブリッド検索で網を広く張って、リランカーで絞り込む、という感じですか?」
「完璧な整理だ!」
まとめ ─ 「カンペ」で賢くなるAIの未来
「今日学んだことを一言でまとめると何ですか?」
「RAGとは、LLMに外部の信頼できる知識をリアルタイムで渡すことで、回答精度を上げてハルシネーションを減らす技術。頭の中だけで答えさせるんじゃなく、その場で正しい資料を見せてあげる。それがRAGだ。」
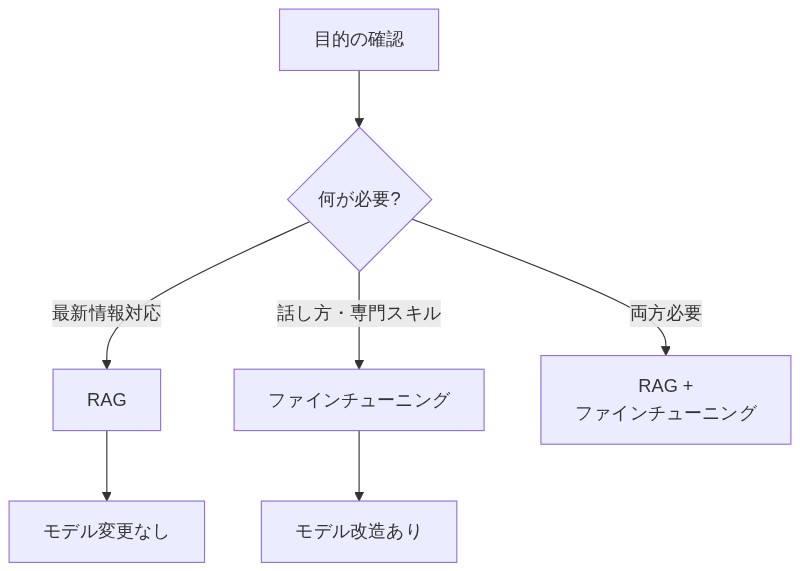
「あと、ファインチューニングって言葉も聞くんですが、RAGと何が違うんですか?」
「いい質問。ファインチューニングはモデル自体を改造する方法。AIの脳みそを書き換えるイメージだ。一方でRAGはモデルは一切変えずに、外部データを参照するだけ。カンペを渡す係を用意するイメージだな。」
「どっちを使えばいいんですか?」
「目的次第だ。最新情報や社内ドキュメントに動的に対応したいならRAG。特定のしゃべり方・専門スキルをモデル自体に身に付けさせたいならファインチューニング。この2つは対立するものじゃなくて、用途に応じて使い分けるものだと覚えておこう。」
| 従来のLLM | RAG付きLLM | ファインチューニング | |
|---|---|---|---|
| 最新情報への対応 | ✗ できない | ✓ 動的に参照可能 | △ 再学習が必要 |
| 社内・専門情報 | ✗ 対応不可 | ✓ 外部DBで対応 | △ 学習データ次第 |
| ハルシネーション対策 | 弱い | ✓ 有効 | ─ |
| モデル本体の変更 | なし | なし | あり |
「RAGはカンペを渡す技術、ファインチューニングはAI自体を鍛える技術、ですね!」
「完璧!今日の『カンペを渡す』というイメージを頭に置いておくと、これから実際のコードや実装の話に進んだときにもグッとわかりやすくなるはずだ。ぜひ次のステップに進んでみてくれ。」


コメント