
こんにちは! zhackです!
私は過去に自然言語処理を用いたプロジェクトに参画していました。
その時に学んだことをアウトプットしたいなぁと思ったので、今回から自然言語処理について記事を投稿していきます。
現状、以下の記事を想定してます。
- 単語ベクトルとは(本記事)
- 単語ベクトル作成方法
2.1 Skip-Gram Modelの解説
2.2 CBOW Modelの解説 - 文ベクトル作成方法
- 文章の意味の把握
- 分かち書き・形態素解析
- 日本語と英語の違い
- 自然言語処理とCNN(未定)
※内容は変動する可能性がございます。
今回は、この中でも単語ベクトルについてまとめようと思います。
自然言語処理とは
まず、自然言語とは何でしょうか。それは普段、私たちが利用している言語です。
日本語や英語、フランス語など、人間が会話をするときに使っている言語のことを自然言語と呼びます。
プログラミング等、PCが理解することの言語をプログラミング言語という言語と対比して、人が扱う言語を自然言語と呼ばれます。
この自然言語に対して、なにかしらの処理を行うことを自然言語処理と呼びます。
この自然言語処理の手法について、大別して、
- 自然言語を自然言語のまま、処理を行うもの
- 自然言語を数値情報に変換して、処理を行うもの
の二つ存在します。
本記事で紹介する「単語ベクトル」は二つ目の手法で、
単語を数値情報に変換したものです。
なお、本記事では、対象とする自然言語は英語とします。
日本語については、後日掲載予定です。
自然言語を数値化する!Word2Vec!
Word2Vecとは
「Word2Vec」は、自然言語を「単語ベクトル」に変換する手法を指します。
Word2Vec(word to vector)というように、「単語からベクトルへ」という意味ですね。
では、単語ベクトルとはどのようなものでしょうか。
単語ベクトルとは
数学で、ベクトルについて勉強したことがあると思います。
ベクトルは、例えばXYの2軸で表現される空間内の点を、
原点( 0, 0 )を起点に、( x, y )の形で、座標が表現されているものでした。
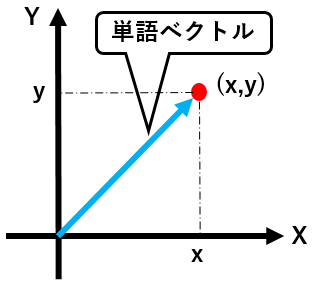
単語ベクトルは、各単語がこの座標空間内の各点に対応させたものになります。
※ただし、実際の座標空間は2次元空間ではなく、多次元空間になることが多いです。
では、どのように各単語を座標空間内の点に対応させるのでしょうか。
単語ベクトルの作成方法
例として、この世の中に、「りんご」「車」「明るい」の三つの単語しか存在しなかった場合、以下のように3次元のベクトルを作ることが一番簡単です。

しかし、実際にはこの世の中には単語が数えきれないほど存在し、上記のようなベクトルを作成することは難しいです。
原理的には可能ですが、非常に多次元な座標空間になってしまいます。
そこで、単語の持つ意味や性質を活用することで、次元数を減らしていきます。
ここでキーワードとなるのは”分散表現”という考え方です。
ベクトルの各要素に単語を割り振るのではなく、各要素には単語を構成する要素が割り振られます。
具体的には、例えば「りんご」を分散表現したい場合、
『赤い』『丸い』『食べ物』の要素から構成するといった感じです。
なにができるのか?
単語ベクトルは数値情報なので、計算をすることができます。
この数値情報は、その単語の意味や性質を表すので、意味や性質の加算や減算ができます。
例えば、
王 - 男 + 女 = 女王
といったことも可能です。
また、ベクトルのコサイン類似度が高いものから、類義語を探したりすることも可能です。
単語ベクトルを使った面白い記事があるので、共有させていただきますね。

アルゴリズム一覧
現状、存在する単語ベクトルの作成方法について一部を掲載します。
- Skip-Gram
- CBOW
こちらについては後日、記事を掲載予定です。
こちらの記事です!


さいごに
なんとなくイメージできましたでしょうか。
今回は、単語ベクトルについて説明しました。
次回は、どのように単語ベクトルを生成するのか、その方法について説明します。
※今回とは異なり、少し技術的な話になります。
ではでは!


コメント
[…] 【自然言語処理】単語ベクトルとは?こんにちは! zhackです! 私は過去に… […]