
こんにちは! zhackです!
今回は単語ベクトルの生成方法の一つ、CBOW Modelについて私の理解を解説していきます。
(今回の記事は、少し内容に自信がありません。。
内容に間違いがある場合はコメントいただけますとありがたいです、、、)
自然言語処理シリーズとして、以下の流れを想定しています。
- 単語ベクトルとは
- 単語ベクトル作成方法
2.1 Skip-Gram Modelの解説
2.2 CBOW Modelの解説 - 文ベクトル作成方法
- 文章の意味の把握
- 分かち書き・形態素解析
- 日本語と英語の違い
- 自然言語処理とCNN(未定)
※内容は変動する可能性がございます。
今回は、この2.2に該当します。
では、いきましょー。
対象読者
今回、対象としている読者は以下のような方です。
- 単語ベクトルが何かわかるけど、どうやって作るのか仕組みを知りたい人
- 単語ベクトル作成の際、気をつけておくべきことを知りたい人
単語ベクトルについて、よくわからない方は以下の記事をご参考ください。

なお、単純に単語ベクトルを作成するプログラムを実装したいという方は、pythonのgensimパッケージを使って関数を呼ぶことで作成することができます。
以下のリンクから使用方法をご確認ください。

CBOW Modelとは
CBOW (Continuous Bag-of-Words) Modelは単語ベクトルの作成方法の一つです。
このモデルの作成で行なっていることは、
「ある単語Aの周辺に存在する単語から、単語Aを推測するネットワークを作成し、そこから単語Aを表すベクトルを抽出する」
です。
簡単に説明すると、Skip-Gramの逆ver.といった感じでしょうか。
では具体的にどのようなことを行なっているのか解説をしていきます。
キーワード
条件付確率
CBOWについて、理解する前に一つ説明しておきたい統計量があります。
それが「条件付き確率」です。Wikipediaにはこう書かれています。
ある事象 B が起こるという条件下での別の事象 A の確率のことをいう。
このように、ただ「事象Aが起こる確率」ではなく「事象Bが起きる条件下で事象Aが起こる確率」という、条件が付いた確率なので、条件付確率といいます。
具体的には、「雨が降る確率」は普通の確率。
「雲一つない条件下で雨が降る確率」は条件付確率。のような感じでしょうか。
では、CBOWの説明に入りましょう。
Fake Task
さて、Skip-Gramの解説の記事と同様に、Fake Taskを行います。
CBOWにおけるFake Taskは「ある単語に着目し、その周辺にある単語を入力としたとき、着目している単語が予測結果として出力される」モデルの構築になります。
では、以下の例文で説明しましょう。
The quick brown fox jumps over the lazy dog.
以降の説明では、着目している単語を着目語、着目語の周辺にある語を周辺語と呼称します。
モデルの作成
モデルの作成の為、入力データ、出力データを準備します。
入力データは周辺語、出力データは着目語になります。
着目している単語からどの程度離れた単語までを周辺語と呼ぶかはウィンドウサイズで決定します。
たとえば、ウィンドウサイズが1のとき、
“The”に着目している場合、周辺語は”quick”になります。
”lazy”に着目している場合は、”the”と“dog”です。
着目している単語の前後ウィンドウサイズ分の単語が周辺語になります。
モデルの作成に必要な学習データとして、この着目している語と周辺語の組み合わせを学習データとして活用します。
以下の画像は、その学習データをウィンドウサイズが2の場合の学習データになります。
Training Samplesは、(周辺語,着目語)で表記しています。

このような入出力データから構成されるモデルは以下のような3層構造のモデルになります。
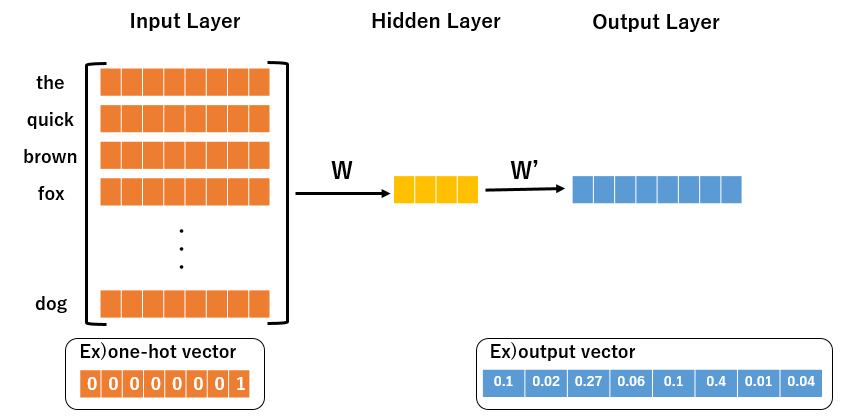
前回解説したSkip-Gram Modelと異なる点は、入力部分になります。
この部分がBOW(Bag of Word)ですね。
(単語がたくさん詰まっている様子から名付けられたのでしょうか、?)
また、出力されるベクトルは各単語の条件付確率になります。
各列の値が単語一つ一つの条件付確率となっています。
今回のモデルでは、周辺語のBOWを入力したときに、着目語に関する条件付確率が最大となるようにモデルを学習させています。
このタスクがCBOWにおけるFake Taskになります。
単語ベクトルの作成
さて、それではこのタスクの結果、単語ベクトルはどのように算出するのでしょうか。
Skip-Gramに関する記事を読まれている方はなんとなくわかると思います。
先ほどの図を簡易的に書くとこのような流れになり、
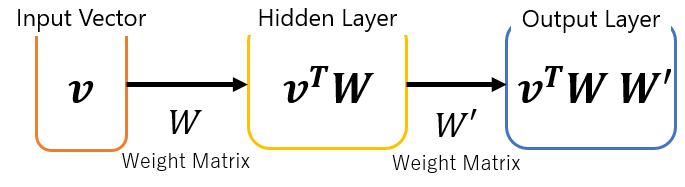
vの各行は、one-hotベクトルとなるので、Skip Gramの時と同様、
隠れ層の行列の各行のベクトルは、単語に対し一意なベクトルとなります。
これを単語ベクトルとして利用します。
以上のように、CBOWモデルによる単語ベクトルが作成されています。
さいごに
以上が、CBOWモデルの解説でした!
なんとなくイメージはできましたでしょうか。
前回のSkip-Gramの解説記事も併せて読んでいただくと、理解が深まると思います。

ではでは!


コメント
[…] 単語ベクトル作成方法 2.1 Skip-Gram Modelの解説 2.2 CBOW Modelの解説 […]