
過学習って何? 「テスト前の丸暗記」で理解する機械学習の落とし穴
「過学習」という言葉、AIや機械学習の記事でよく目にするけど、なんだかとっつきにくいよね。
でも実は、誰もが経験したあの感覚で一発で理解できる。
「テスト前に教科書を丸暗記して、本番では応用問題に全然歯が立たなかった……」
あの経験こそが、過学習のすべてを語っているんだ。
過学習とは? テスト前の丸暗記にたとえると
過学習って一言でいうと何?

「ねえ先生、過学習ってよく聞くんだけど、一言でいうとどういうこと?」
「一言でいうと、“知ってる問題は完璧に解けるのに、初めて見る問題はさっぱり解けないAI” のことだよ。」


「え、それってダメなやつ……?」
「ダメなやつ。正式には過学習(オーバーフィッティング/過剰適合)って呼んで、機械学習モデルが訓練データに過剰に適合しすぎてしまい、未知の新しいデータには正確な予測ができなくなった状態のことを言う。」

テスト前の丸暗記と何が同じなの?

「訓練データ、未知のデータ……なんかピンと来ないんだよなあ。」
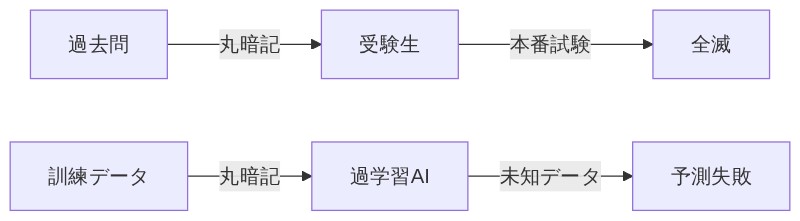
「じゃあ学校の勉強で考えてみよう。テスト前夜に、去年の過去問を全部丸暗記したとする。問題の答えを内容を理解せずただ覚えた状態ね。」

「あ、それやったことある! 過去問は全部解けるのに、本番で少し違う問題が出たら全滅した……。」
「それが過学習そのものだよ。過去問=訓練データ、本番の試験=未知の新しいデータ。丸暗記した受験生(=過学習したAI)は、知ってる問題は100点でも、ちょっと変化球が来た瞬間に崩れる。」
過学習だと何が困るの?
「でも訓練データで精度が高いなら、それでよくない?」
「機械学習の本当の目的は、訓練データを完璧に当てることじゃないんだ。実際に世の中に出回る、モデルが一度も見たことがないデータを正確に予測することが目的なんだよ。」
「つまり、訓練データだけパーフェクトでも意味がない……?」
「そう。過学習のモデルは訓練誤差(訓練データでの間違い)は小さいけど、汎化誤差(未知データでの間違い)は全然小さくならない。それがこの問題の本質だね。実世界では役に立たないAIの出来上がりってわけ。」
なぜ過学習が起きるのか — 「覚えすぎる」AIの仕組み
どういうときに過学習は起きやすい?
「過学習が起きる原因ってどういうとき?」
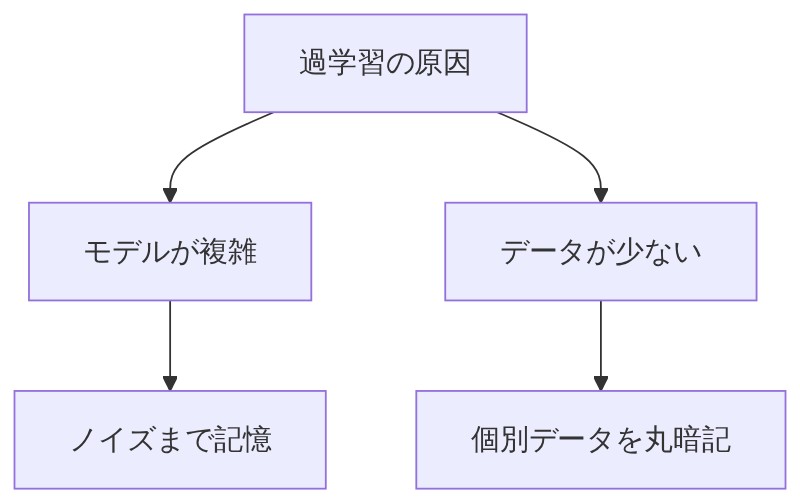
「大きく2パターンある。①モデルが複雑すぎるときと、②データが少なすぎるときだ。」
モデルが複雑だとなぜダメなの?
「モデルが複雑すぎるってどういうこと?」
「モデルを、”データの形を真似する曲線を描く機械”だと思ってほしい。複雑なモデルはものすごく曲がりくねった曲線を描ける。データの細かいデコボコ、たまたまそこにあっただけのノイズ(本来意味のない情報)まで完璧にトレースしてしまう。」

「あーなるほど、丸暗記した受験生が”この問題はこのページの左上に書いてあった”みたいなところまで覚えてるのと同じか。」
「ナイス比喩! まさにそれ。本質を理解せず、どうでもいい細かいところまで覚え込んじゃってる状態ね。シンプルなモデルは訓練データへの適合が少し荒くなるけど、新しいデータへの汎化性能は複雑なモデルより良いことが多い。」
データが少ないとなぜ起きるの?
「データが少ないと過学習が起きるのはなんで?」
「たとえば”猫を見分けるAI”を教えたいのに、訓練データが3枚しかなかったとする。そのAIは猫の本質的な特徴(耳の形、ひげなど)を学ぶんじゃなくて、その3枚の画像そのものを丸暗記してしまうんだ。」
「少ししか例がないから、その例自体を覚えちゃうのか。」
「そう。データが多ければ多いほど、モデルは”個々の丸暗記”じゃなく”共通するパターン(本質)”を学べる。これを汎化というんだ。ちょっと丸暗記 vs 理解の比喩そのままだろ?」
過学習をどう見つける? — 訓練の成績とテストの成績を比べる
自分のモデルが過学習かどうやって確かめる?
「で、自分のモデルが過学習してるかどうか、どうやって気づくの?」
「基本は成績表を2枚並べること。訓練データでの成績と、テストデータでの成績を見比べるんだ。」
「2枚の成績表……?」
「訓練データのスコアが高いのに、テストデータのスコアが低い。このギャップが大きいほど、過学習が疑わしい。模擬試験(過去問)は満点なのに、本番テストは散々だった、あの感じだよ。」
訓練データとテストデータを分けるのはなぜ?
「なんでそもそもデータを分けないといけないの?」
「答えを事前に知ってる問題でテストしても意味がないからだよ。モデルが一度も見たことがないデータで採点しないと、本当の実力が測れない。だから最初からデータを”練習用(訓練データ)”と”テスト用(テストデータ)”に分けておくんだ。」
学習曲線って何?どう読むの?
「学習曲線って言葉も聞くんだけど。」
「学習曲線は、学習が進むにつれて訓練誤差と汎化誤差がどう変わっていくかをグラフにしたものだ。」
「どんな形になるの?」
「最初は2本の線がどちらも下がっていく。でもある時点から、訓練誤差は下がり続けるのに、汎化誤差だけが上がり始める。この”V字に乖離していく瞬間”が、モデルが丸暗記モードに入ったサインだよ。」


「なるほど、グラフで見れば一目瞭然なんだ!」
対策の基本 — データを増やす・単純にする・早めに止める
過学習に気づいたらまず何をすればいい?
「過学習してたら、まず何をすればいい?」
「王道の対策は3つ。データを増やす・モデルを単純にする・早めに止めるだ。」
「シンプルだ!」
「まず一番効くのはデータを増やすこと。さっきの”猫3枚問題”が1000枚になれば、丸暗記じゃなくパターン学習ができる。次に、モデルをあえてシンプルにする。覚えられる容量を減らして、本質的なパターンだけに集中させるイメージだな。」
早期終了(Early Stopping)って何?
「早めに止めるっていうのは?」
「早期終了(Early Stopping)という技だよ。学習中に検証データの誤差を監視しておいて、”ここから先は悪化してるな”というタイミングで学習をパッと打ち切る手法だ。」
「あ、過学習が始まる手前でやめちゃうのか。」
「そう。受験勉強でいえば、”ここ以上は細かすぎる丸暗記になるから今夜の勉強はここまで!”って判断するのと似てる。ちょうどいいところで手を止めるのが大事なんだよ。」
データ拡張って何をするの?
「データを増やすって言っても、そんな簡単に増えないよね?」
「そこで登場するのがデータ拡張(Data Augmentation)だ。既存のデータを加工して新しいデータを人工的に作り出す手法で、たとえば猫の画像なら左右反転させたり、少し明るさを変えたり、傾けたりして水増しする。」
「同じ猫の写真なのに、いろんな角度やライティングで見ることで、”猫らしさ”のエッセンスを学べるようになるんだ。」
「なるほど、同じ教材でも見方を変えて練習する、みたいな感じか!」
正則化とドロップアウト — 「覚えすぎ」にブレーキをかける技術
正則化って何をしているの?
「正則化って言葉も聞くんだけど、何をしてるの?」
「正則化は、モデルが”覚えすぎようとする”とペナルティを課す仕組みだよ。機械学習モデルの内部には”重み”と呼ばれるパラメータがいっぱいあって、この重みが大きくなりすぎると細かいデータまでビタッと合わせようとする。そこで損失関数(モデルの間違いを測る式)に”重みが大きいと余計に点数が引かれる”項を追加して、過剰に大きくなるのをブレーキする仕組みだ。」
「試験でいえば、”余白に関係ないメモを書きすぎたら減点”みたいなルール?」
「その比喩めちゃくちゃいいな。まさにそれ。余計な情報を詰め込みすぎると損するルールを設けることで、シンプルで本質的な解を促すんだよ。」
L1とL2の違いは?
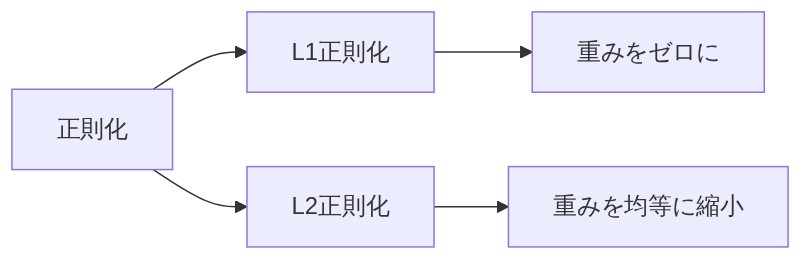
「L1正則化、L2正則化って出てくるんだけど、違いは?」
「ざっくりいうと、L1は”邪魔な重みを完全に0にする”、L2は”全体の重みをまんべんなく小さくする”違いだ。L1は重要じゃない特徴量をバサッと切り捨ててシンプルにする力があって、L2は全体をほどよく抑える力がある。実務では過学習を抑えるのにL2がよく使われるよ。」
ドロップアウトはなぜ効くの?
「ドロップアウトってかっこいい名前だけど何?」
「ニューラルネットワークの学習中に、ランダムにいくつかのニューロン(脳の神経細胞みたいなもの)を一時的に無効化する手法だよ。」
「え、わざと壊すの?」
「壊すというより、”欠席させる”イメージ。毎回違うメンバーが欠席する中でも正しく予測できるよう訓練することで、ニューロン同士が”あいつがいないと俺たちは機能しない”みたいな過剰な共依存を防ぐんだ。」
「一人に頼りすぎないチームを作るんだ!」
「まさに! Srivastava・Hintonらが2014年に発表した手法で、画像認識や音声認識など多くのタスクで過学習を大幅に減らし、当時の最高性能を出したことで広く知られるようになった。」
まとめ — 丸暗記でも勉強不足でもなく「理解」を目指す
過学習の反対(未学習)もあるの?
「過学習の逆ってあるの?」
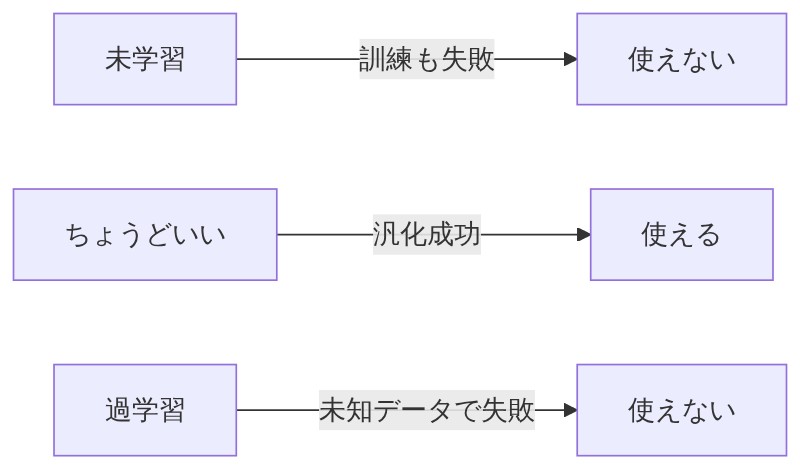
「あるよ。未学習(アンダーフィッティング)だ。モデルが単純すぎてデータのパターンを全然捉えられない状態で、訓練データすらまともに当てられない。」
「それは……勉強しなさすぎて過去問も解けない状態か。」
「そう。丸暗記しすぎ=過学習、勉強不足=未学習。どっちも本番(実世界のデータ)では使い物にならない。」
ちょうどいいモデルはどう探す?
「じゃあちょうどいいモデルってどう探すの?」
「これが機械学習の核心的な難しさで、バイアスとバリアンスのトレードオフっていう概念がある。」
「なんか難しそう……。」
「難しく考えなくていい。”単純すぎるモデル(バイアスが大きい)”と”複雑すぎるモデル(バリアンスが大きい)”のどちらにも振れすぎない甘いスポットを探す作業だよ。モデルの複雑さを調整したり、正則化したり、データを増やしたりしながら、その甘いスポットを探っていくんだ。」
「結局、テストで高得点を取るのと同じで、”丸暗記でも勉強不足でもなく、本質を理解すること”を目指すんだね。」
「完璧な理解だよ。そして最終的に大事なのは、汎化性能——新しいデータに対して正しく予測できること。モデルの本当の実力は訓練データじゃなく、未知のデータで測られる。それが機械学習の本当のゴールだ。」
結局なにを覚えておけばいい?
「まとめると?」
「3行で言うよ。」
- 過学習 = 訓練データは完璧、未知データはボロボロ(丸暗記)
- 未学習 = 訓練データすら解けない(勉強不足)
- ゴール = 汎化性能を高めて、未知のデータでも正確に予測できるモデルを作ること
「対策は、データを増やす・モデルをシンプルにする・早期終了・正則化・ドロップアウト。まずはこのセットを頭に入れとけば十分だよ。」
過学習がつかめてきたら、次のステップとして既存のモデルを自分のデータに合わせて調整するファインチューニングという考え方も面白いぞ。興味がある人は ファインチューニングとは–料理のレシピで理解するAIの「味付け直し」 も覗いてみてね。
また、機械学習全体を体系的に学びたい人には 【G検定合格】勉強法、おすすめ参考書、すべて公開します! もあわせて参考にどうぞ。
この記事のポイント(まとめ)
訓練データの成績 未知データの成績 未学習 悪い 悪い ちょうどいい 良い 良い 過学習 とても良い 悪い
- 過学習の原因:モデルが複雑すぎる・データが少ない
- 主な対策:データ増強・早期終了・正則化・ドロップアウト
- 本当のゴール:汎化性能を高めること
参考文献
- https://aws.amazon.com/what-is/overfitting/
- https://www.ibm.com/think/topics/overfitting
- https://www.nri.com/jp/knowledge/glossary/overfitting.html
- https://e-words.jp/w/%E9%81%8E%E5%AD%A6%E7%BF%92.html
- https://developers.google.com/machine-learning/crash-course/overfitting/overfitting
- https://developers.google.com/machine-learning/crash-course/overfitting/model-complexity
- https://axa.biopapyrus.jp/machine-learning/model-evaluation/learning-curves.html
- https://www.netattest.com/overfitting-2024_mkt_tst
- https://www.lenovo.com/us/en/knowledgebase/understanding-overfitting-in-machine-learning-causes-impacts-and-solutions/
- https://towardsdatascience.com/8-simple-techniques-to-prevent-overfitting-4d443da2ef7d/
- https://eureka.patsnap.com/report-how-to-use-data-augmentation-to-prevent-overfitting
- https://ja.wikipedia.org/wiki/%E6%AD%A3%E5%89%87%E5%8C%96
- https://zero2one.jp/learningblog/yobinori-collab-regularization/
- https://www.jmlr.org/papers/v15/srivastava14a.html
- https://developers.google.com/machine-learning/crash-course/overfitting/regularization

コメント