強化学習をゲームで掴む ── AIが「試行錯誤」で賢くなる仕組み
「AlphaGoが囲碁の世界チャンピオンに勝った」「AIがAtariのゲームを人間より上手く攻略した」── そんなニュースを見て、「どうやって学習してるんだろう?」と気になった人、いますよね。今回はそんな疑問に、RPGのたとえを使いながらやさしく答えていきます。

「AlphaGoってさ、誰かがゲームの攻略法を全部教えたわけじゃないんでしょ?どうやって強くなったの?」
「いい質問!あれは強化学習ってやり方でAIが自分で試行錯誤して強くなったんだよ。まるでRPGのキャラが冒険しながら経験値を積んで成長するイメージに近い。順番に説明するな!」

教師あり学習との違い ── 「答え付きドリル」と「自分で冒険」
機械学習の3兄弟
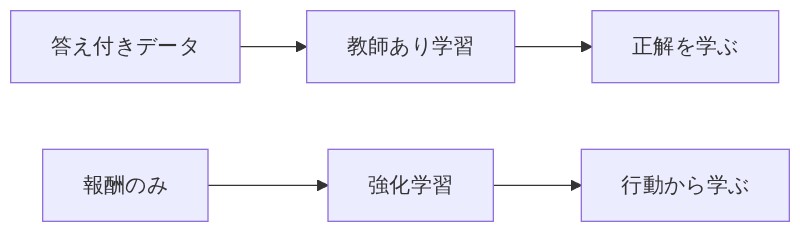
まず、機械学習には大きく分けていくつかの種類があります。今回の主役「強化学習」を理解するために、よく聞く「教師あり学習」と何が違うかを整理しましょう。

「先生、そもそも教師あり学習って何ですか?」
「教師あり学習は、答え付きの問題集をひたすら解かせるイメージだな。たとえば『この写真は猫です』『これは犬です』ってラベルがついたデータを大量に見せて、AIに”猫と犬の見分け方”を覚えさせる方法だよ。」


「じゃあ強化学習は?」
「強化学習は答えが最初からない。RPGで言えば、攻略本なしで自分でダンジョンに飛び込んで、死んだり宝を見つけたりしながら『この部屋でこの行動は危険だな』って覚えていくイメージ。正解を誰かに教わるんじゃなくて、行動の結果から学ぶんだ。」
| 学習の種類 | たとえ | 何から学ぶ? |
|---|---|---|
| 教師あり学習 | 答え付きドリルを解く | 正解ラベル付きのデータ |
| 強化学習 | 攻略本なしで冒険する | 行動の結果(報酬) |
「なるほど〜!答えがないのに学習できるって不思議だな。」
「そこが強化学習の面白いところで、ゲーム攻略・ロボット制御・最適化問題みたいに”正解がそもそも用意しにくい問題”にめちゃくちゃ向いてるんだよ。」

エージェントと環境 ── RPGの主人公とダンジョン
強化学習を動かす2つの主役
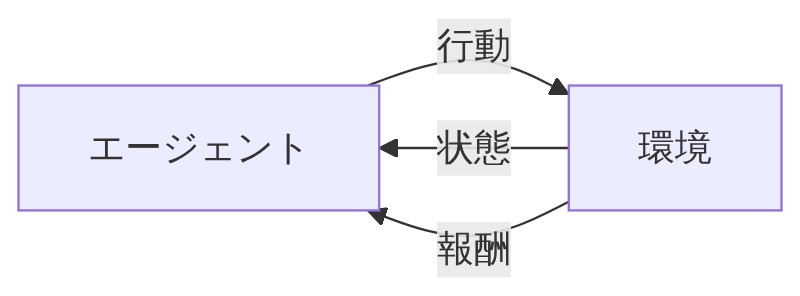
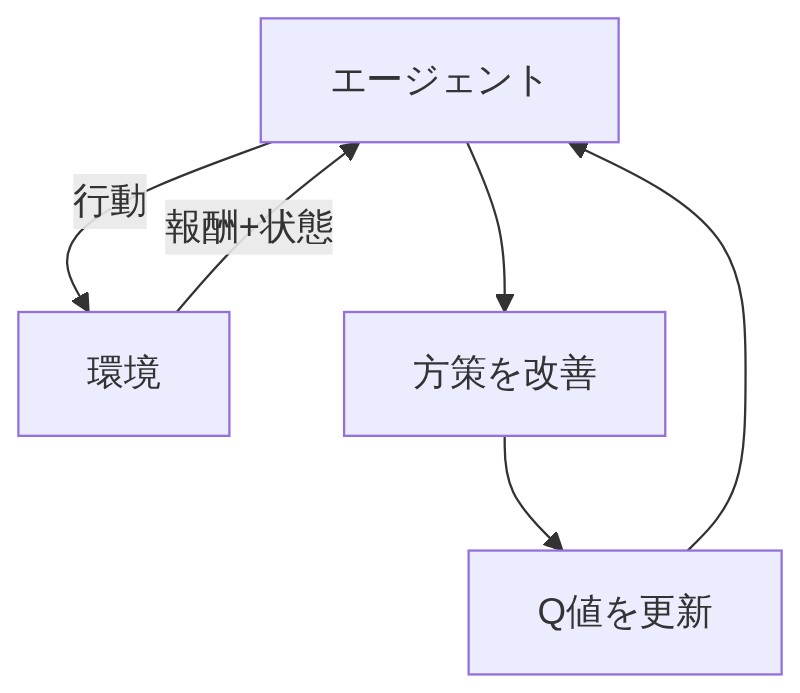
強化学習の仕組みには「エージェント」と「環境」という2つの構成要素があります。難しそうに聞こえますが、RPGに当てはめると一気にわかりやすくなります。
「エージェントって何ですか?」
「RPGで言えば主人公(プレイヤーキャラ)だな。ダンジョンの中で状況を見て、行動を選んで、その結果に応じて成長していく存在だよ。」
「じゃあ環境は?」
「環境はダンジョン(ゲームの世界)そのもの。主人公が行動すると、ダンジョンが『お前の行動を受け取ったぞ、次の状況はこうだ、報酬はこれだ』って返してくる。」
状態・行動・報酬 ── 3つの情報の受け渡し
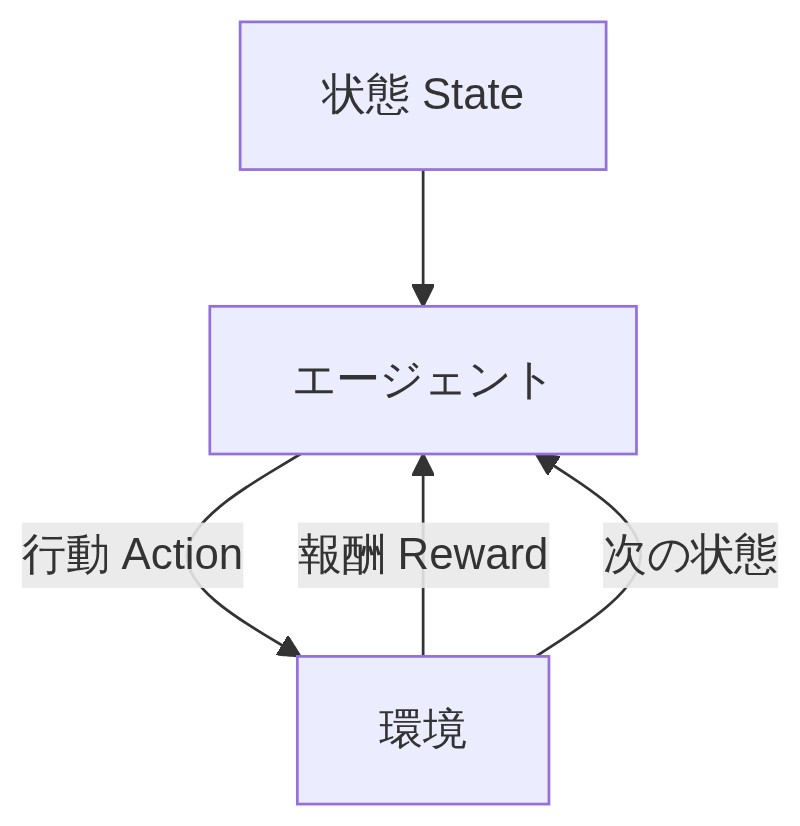
強化学習では、エージェントと環境が以下の3つの情報を受け渡しながら学習が進みます。
「状態(State)はいまダンジョンのどの部屋にいるか、HPはいくつか、敵はどこにいるか、という現在の情報。
行動(Action)は主人公が選ぶ選択肢── 攻撃する、逃げる、アイテムを使うとか。
報酬(Reward)は行動の結果として環境から返ってくる数値の評価だよ。敵を倒したら+100点、穴に落ちたら-50点みたいなイメージ。」
「報酬がプラスになったり、マイナスになったりするんですね。」
「そう!望ましい行動には高い報酬、望ましくない行動には低いかマイナスの報酬が設計される。で、エージェントの目標は長い目で見て報酬の合計をできるだけ大きくすることだ。」
報酬設計は「ゲームバランス」と同じ
「ところで、その報酬って誰が決めるんですか?」
「設計者が決めるんだよ。そしてこれが強化学習の成否を大きく左右する超重要なポイント。ゲームで言えば『経験値の設計』みたいなもの。スライムを倒しても経験値がゼロだったら、プレイヤーは雑魚を無視してボスに突っ込もうとするよね?」

「確かに、設計が悪いとおかしな行動を覚えちゃいそう……!」
「そのとおり。報酬をうまく設計しないと、AIが意図と全然違う”抜け道”を学習しちゃうことがある。それくらい報酬設計は強化学習の肝なんだ。」
方策と価値関数 ── 「どの道を選ぶか」の戦略
方策(Policy)── 主人公の「行動指針」
「強化学習でよく出てくる『方策』って何ですか?」
「方策は一言で言うと『状況に応じてどう動くかの戦略』だよ。RPGで言えば、『ボスがHPの半分を切ったら全力攻撃に切り替える』『毒エリアでは常に解毒ポーションを持っておく』みたいな行動ルールのことだな。」
「その方策は試行錯誤で良くなっていくんですか?」
「そう!最初はでたらめな方策でも、報酬のフィードバックを受けながら繰り返し改善されていく。まるで初心者プレイヤーがやり直しを重ねてうまくなるのと同じだよ。」
価値関数 ── 「この場所、どれくらいいい場所?」
「価値関数っていうのも聞きます。これは何ですか?」
「価値関数は各状態や行動の『将来的な良さ』を数値で表したものだよ。たとえば『ボスの手前の部屋』は宝が近いからスコアが高い、『即死トラップの前』はスコアが低い、みたいな感じ。今の行動が未来の報酬にどう響くかを見積もってる。」

探索と活用 ── 開拓派と安全策派のジレンマ
「方策が決まったら、ずっとその通りに動けばいいんじゃないですか?」
「それが落とし穴でね。『知ってる道だけ歩き続ける』ともっと良い道を見落としちゃうかもしれない。でも『常に知らない道を試す』と効率が悪い。この探索(新しい行動を試す)と活用(今知ってるベストな行動を使う)のバランスをとるのが、強化学習の大事な課題なんだ。」

「RPGで言うと、メインストーリーだけ進めるか、寄り道してサブクエストも探るか、みたいな?」
「ドンピシャ!メインだけ進むと強くなるのに限界があるけど、寄り道ばかりしてるとボスにたどり着けない。そのバランスをどう取るかがAIの設計上の腕の見せどころだな。」
Q学習の直感 ── 「この場面でこの行動はどのくらい有利?」
Q値 ── 「この手、何点?」
「Q学習ってよく聞くんですけど、Q値って何ですか?」
「Q値は『この状況でこの行動を選んだとき、将来どれくらい良い報酬が期待できるか』を表す数値だよ。Qが高いほど『その行動を選ぶ価値がある』ってことになる。」
「RPGで言うと?」
「ボスとの戦闘で『全力攻撃ボタン』を押したときのQ値が高くて、『その場で踊る』のQ値がめちゃくちゃ低い、みたいな感じだな(笑)。エージェントはQ値が一番高い行動を選ぼうとするわけ。」
Q値はどうやって更新されるのか
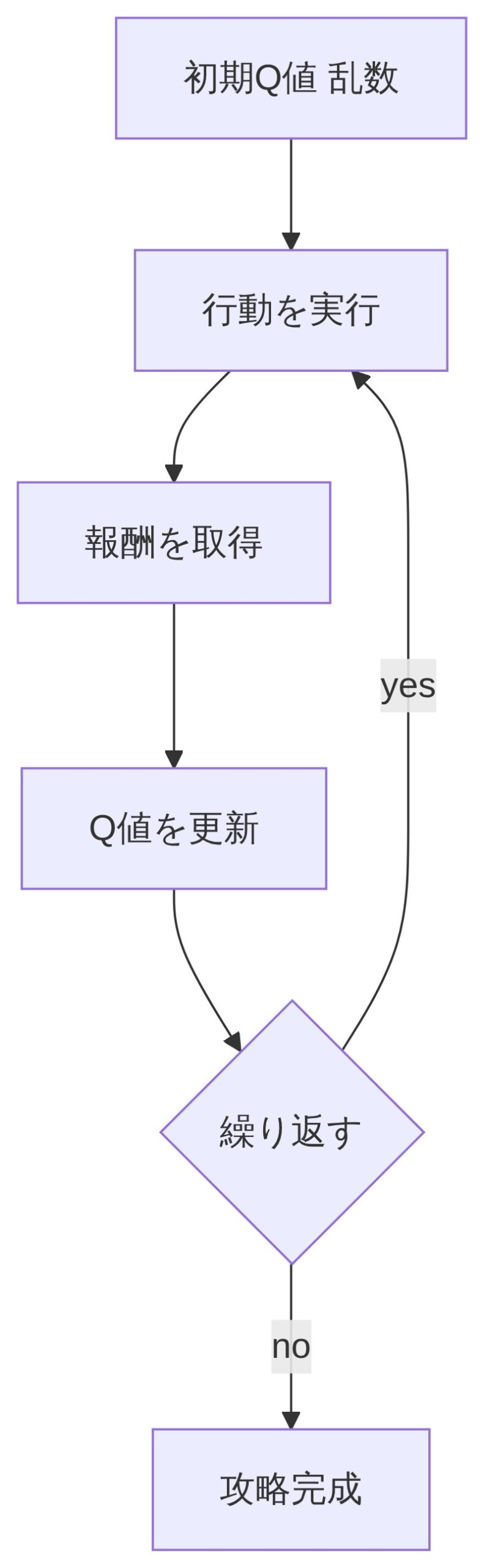
「でも最初はQ値がわからないですよね?」
「そう、最初は全部デタラメな数値から始まる。で、実際に行動してみて報酬を受け取るたびに、Q値を少しずつ修正していくんだ。良い結果が出た行動のQ値は上がって、悪い結果が出た行動のQ値は下がる。これを繰り返すことで、だんだん正確な”価値の地図”が出来上がっていく。」
「ゲームを何周もしてるうちに攻略法が固まっていく感じですね!」
「まさに。で、このQ学習には一つ弱点があって、状況の種類が爆発的に多くなると、全部の状況×行動のQ値を表に記録しきれなくなる。たとえばAtariのゲームだと、画面のドットの並びが状況になるから、パターンが天文学的な数になるんだ。」
「そんなの覚えられないですよね……」
DQN ── ニューラルネットが「Q値推定機」になる
「そこで登場するのがDQN(Deep Q-Network)だよ。Q値の表をすべて記録しようとするんじゃなくて、ディープニューラルネットワークに『この状況を入力したら、どの行動のQ値がどのくらいか』を推測させるんだ。」
「ニューラルネットをQ値の計算機として使う、みたいなイメージですか?」
「ナイス理解!Q値推定マシンをニューラルネットで作ることで、見たことない状況でも『こういう場面に似てるからこの行動が良さそう』って推測できるようになる。これによってQ学習が大規模な状態空間を持つ問題にも使えるように拡張されたんだ。」
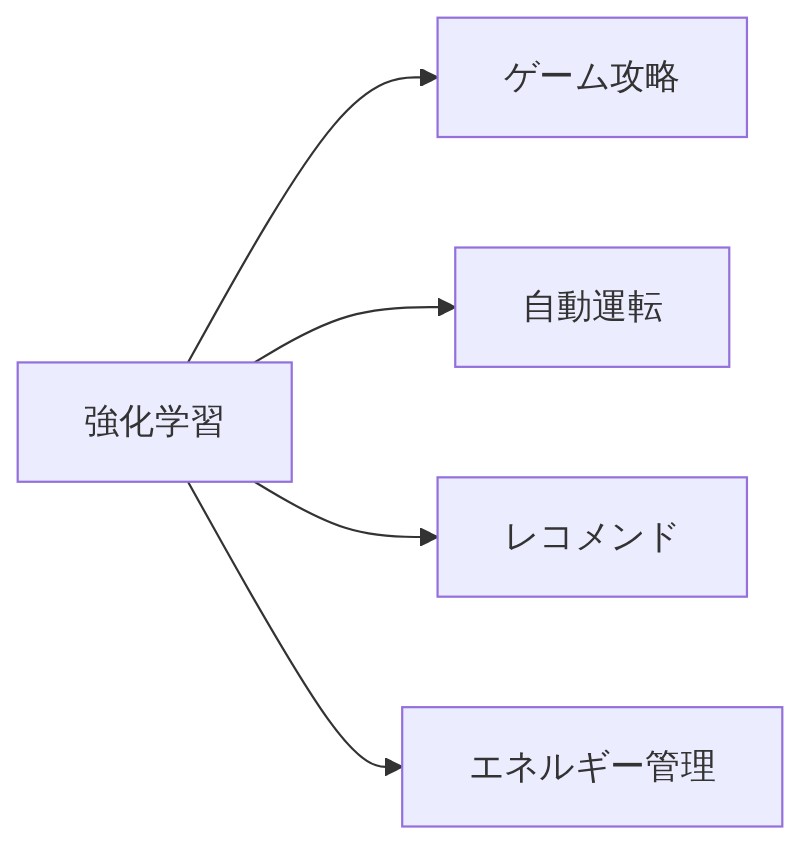
強化学習が活躍している現場 ── AlphaGoから自動運転まで
AlphaGo ── 囲碁の世界チャンピオンを倒したAI
「そういえば最初に出てきたAlphaGoって、どうやって強くなったんですか?」
「AlphaGoはGoogleが作ったAIで、強化学習を使って2015年10月に囲碁の最強棋士を破ったんだ。すごいのは、対戦を重ねるたびにどんどん強くなり続けたこと。最初は人間の棋譜データも使って学習してるんだけど、強化学習で自分同士で何千万局も対戦を繰り返して、人間が思いつかないような一手を編み出していったんだよ。」
「自分自身と戦い続けて強くなるなんて、まるでハードモードで修行してる感じ……!」
自動運転 ── リアルダンジョンをリアルタイムで走る
「自動運転にも使われてるんですよね?」
「そう。たとえばTeslaのAutopilotは深層強化学習を活用して、車線検出・障害物回避・リアルタイムの運転判断を改善してるんだ。走行データを積み重ねるごとに、運転行動が洗練されていく。公道がまさに”ダンジョン”で、安全な走行が”高報酬”という設計だな。」
「失敗したら本当に危険ですよね……報酬設計が超重要そう。」
「そのとおり!だからシミュレーション環境で大量に学習させてから現実に移す方法も使われてるよ。」
意外な応用 ── 動画配信からビルのエネルギーまで
「ゲームや自動運転以外にも使われてるんですか?」
「めちゃくちゃ広いんだよ!たとえばNetflixやAmazonは強化学習をレコメンドシステムに活用して、ユーザー体験と満足度を大幅に向上させてる。これも『ユーザーが動画を最後まで見てくれた→高報酬』みたいな設計になってるわけ。」
「確かに、おすすめが当たるほど満足度上がりますよね!」
「さらに意外なところで言うと、ビルのエネルギー消費の最適化にも使われてて、コスト削減と環境保全に貢献してる。エアコンや照明を『今この状況でこう動かすのが一番効率的』ってAIが判断するんだ。ゲームとは全然違う世界で活躍してるだろ?」
「RPGのスキルが意外な場面で役立つみたいな感じですね(笑)」
まとめ ── 試行錯誤から始まるAIの冒険
「最後に、強化学習を一言でまとめると何ですか?」
「エージェントが環境との試行錯誤を通じて、報酬を最大化する行動を自律的に学習する手法、だな。答えを教えてもらうんじゃなくて、自分で冒険しながら賢くなる仕組みだ。」
「RPGに例えると全部つながりますね!」
「そう!まとめるとこうなる。」
| 強化学習の概念 | RPGで言うと |
|---|---|
| エージェント | 主人公(プレイヤーキャラ) |
| 環境 | ダンジョン(ゲームの世界) |
| 状態 | 現在の場所・HP・敵の位置 |
| 行動 | 攻撃・逃げる・アイテム使用 |
| 報酬 | 経験値・ダメージ |
| 方策 | 攻略スタイル・行動指針 |
| Q値 | 「この場面でこの行動、何点?」 |
| 探索と活用 | 寄り道 vs メインルート |
次のステップ
「強化学習に興味が出たら、次は何を勉強すればいいですか?」
「まずQ学習のコードを自分で動かしてみるのがオススメだよ。シンプルな迷路ゲームを題材にしたチュートリアルが無料でいっぱい公開されてる。動くコードを見ると『ああ、Q値がこうやって更新されるのか』って一気に腹落ちするはずだ。その次にニューラルネットを組み合わせたDQNに挑戦すると、流れが自然につながるよ。」
「まずは迷路を攻略するAIを自分で作るところから、ですね!」
「そう!最初は小さなダンジョンでいい。試行錯誤はAIだけじゃなくて、学ぶ人間にも大事なスキルだからな。」
強化学習のポイントおさらい
- 強化学習は「答えなしで冒険して学ぶ」仕組み。教師あり学習の「答え付きドリル」とは根本的に違う
- エージェント(主人公)が環境(ダンジョン)の中で行動し、報酬を受け取りながら方策を改善していく
- Q値は「この場面でこの行動がどれくらいお得か」を数値化したもので、DQNはニューラルネットでそれを推定する
- AlphaGo・自動運転・レコメンド・エネルギー管理など、幅広い分野でリアルに活躍している
さあ、あなたもAIの「冒険の書」のページをめくってみませんか?

コメント