注意機構(Attention)を5分で掴む ─ 翻訳タスクで追う「どこを見るか」の仕組み

「先生、ニュースで Attention is All You Need って論文名を見たんですけど、Attention って何ですか?」
「おっ、いいところに目をつけたな。Attention ── 日本語でいう”注意機構”は、いまの AI 翻訳や ChatGPT みたいな大規模言語モデルの心臓部になってる仕組みだ。今日は数式ゼロで、図書館で本を探す比喩だけで全部わかるようにしてやるよ。」


「数式ゼロ!それは助かります!」
なぜ「全部を同じように見る」ではダメなのか?
RNN は「情報をカバンに詰め込む」方式だった
Attention が登場する前、機械翻訳の主役は RNN(再帰型ニューラルネットワーク) だった。
「RNN って何をしてたんですか?」
「単語を先頭から1個ずつ読んで、読むたびに『今まで読んだ情報』を1つの固定サイズのカバンに詰め込んで次へ渡す、っていう逐次処理方式だ。」

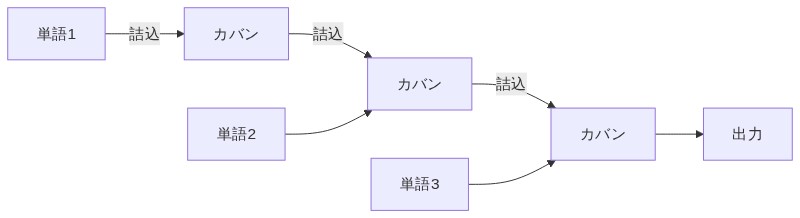

「カバン……固定サイズってことは、入れられる量に限界があるってこと?」
「その通り!短い文ならいいんだが、文が長くなると最初の方に入れた情報がどんどん上書きされて薄まっていく。これを長距離依存問題って呼ぶ。たとえば『昨日、友達と駅の近くにある少し高めのイタリアンレストランで食べたパスタ』みたいな長い文だと、”昨日”って情報が文末に届くころにはカバンの奥底に埋まってるイメージだな。」

「それじゃあ翻訳がおかしくなりますよね……。」
「そう。実際、文が長いほど翻訳精度が著しく落ちることが問題になってた。LSTM や GRU っていう改良版も出て、ゲート機構で多少マシにはなったんだけど、逐次処理の根本的な制約は取り除けなかった。」
Attention の登場
「2014年に Bahdanau たちが『文を翻訳するとき、毎回入力文全体を見渡して関連する部分を動的に参照できるようにしよう』というアイデアを論文で発表した。これが Attention 機構の始まりだ。」

「毎回全体を見渡せるなら、最初の単語を忘れずに済みますね!」
「まさに。そして 2017 年には Vaswani たちが『Attention is All You Need』でRNN を完全に取り除き、Attention だけで作った Transformer を発表した。ここから AI 翻訳の世界がガラッと変わるんだ。」
注意機構のキホン ─ 「どこに注目するか」をスコアで決める
スコアって何を計算してるの?
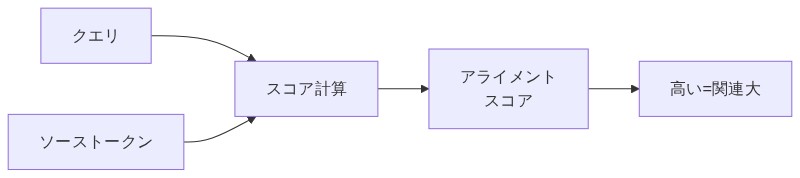
「Attention の考え方はシンプルだ。『今から”cat”を英語に訳すとき、入力文のどの単語が一番役に立つか?』をスコアで数値化する。」
「スコアはどうやって計算するんですか?」
「今の出力したい情報(クエリ)と、入力文の各単語(ソーストークン)の”相性の良さ”を計算する。これがアライメントスコアと呼ばれるものだ。相性が高いほどスコアが大きくなる。」
softmax で「割合」に変換する
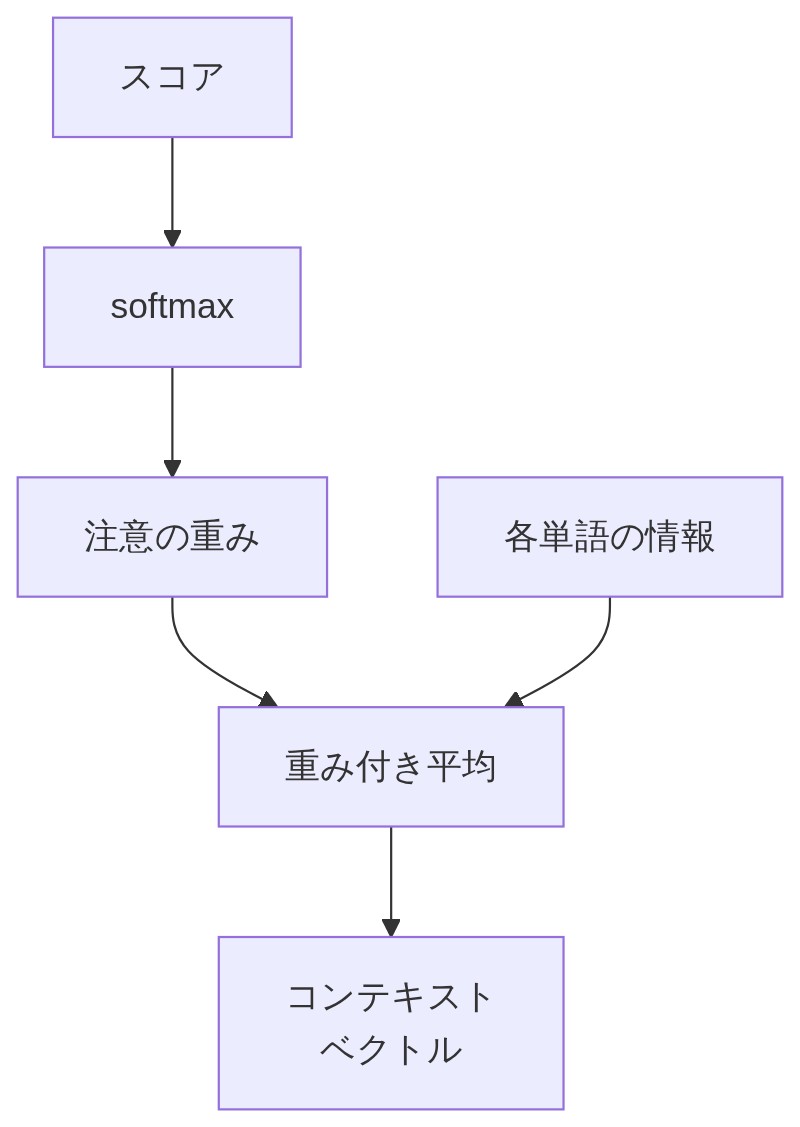
「スコアをそのまま使わず、softmax 関数を通す。すると全スコアが 0〜1 に収まり、しかも合計がちょうど 1 になる確率分布に変わる。」
「割合になるってこと?」
「そう!たとえば『”cat”を訳すとき、入力文の “猫” に 70%、”は” に 20%、”可愛い” に 10% 注目します』みたいな感じだ。これが注意の重み(Attention Weight)になる。」
コンテキストベクトルって何?
「この注意の重みを使って、入力文の各単語の情報を重み付き平均してまとめたものがコンテキストベクトルだ。」
「重み付き平均……?」
「普通の平均は全員を同じ比重で足して割る、だよな。重み付き平均は『重要な人の意見を多め、そうでない人を少なめにして混ぜる』イメージだ。注目度 70% の “猫” の情報はたっぷり、10% の “可愛い” の情報は少し、という割合で混ぜ合わせた要約ベクトルがコンテキストベクトルになる。このベクトルが次の単語を生成するヒントとして使われる。」
Q・K・V って何? ─ 図書館で本を探す比喩で理解する
「ここからが Attention の核心、Query(Q)・Key(K)・Value(V) の3つの役割だ。難しそうに見えるけど、図書館の比喩で一発でわかる。」
「図書館!どんな比喩ですか?」
図書館で考えよう
| 図書館 | Attention |
|---|---|
| あなたが探したいテーマ・質問 | Query(Q):今知りたいこと |
| 本の背表紙のラベル(索引) | Key(K):各単語が持つ「見出し情報」 |
| 本の中身(実際の内容) | Value(V):実際に取り出す情報 |
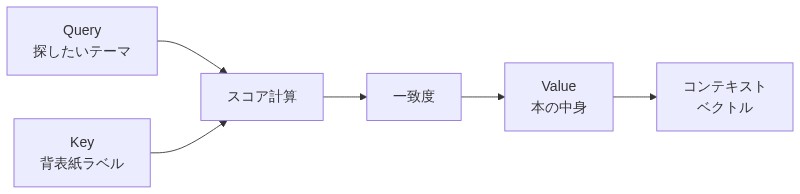
「あなたが図書館で『機械学習の入門書が欲しい』と思ったとする。それが Q だ。棚に並んだ本の背表紙ラベル(K)を順番に見て、一致度の高い本ほど高いスコアをつける。そして一致度の重みに応じて本の中身(V)を取り出す。それがコンテキストベクトルだ。」
「Q と K でどれだけ一致するか測って、その比率で V を混ぜ合わせるんですね!」
「完璧な理解!」
Scaled Dot-Product Attention の計算ステップ
具体的な計算は次の4ステップだ。
① Q と K の転置の内積 → 類似度スコアを計算
② 次元数 d の平方根(√d)で割る → スケーリング
③ softmax を通す → 注意の重みに変換
④ V に掛ける → 重み付き和=コンテキストベクトル完成
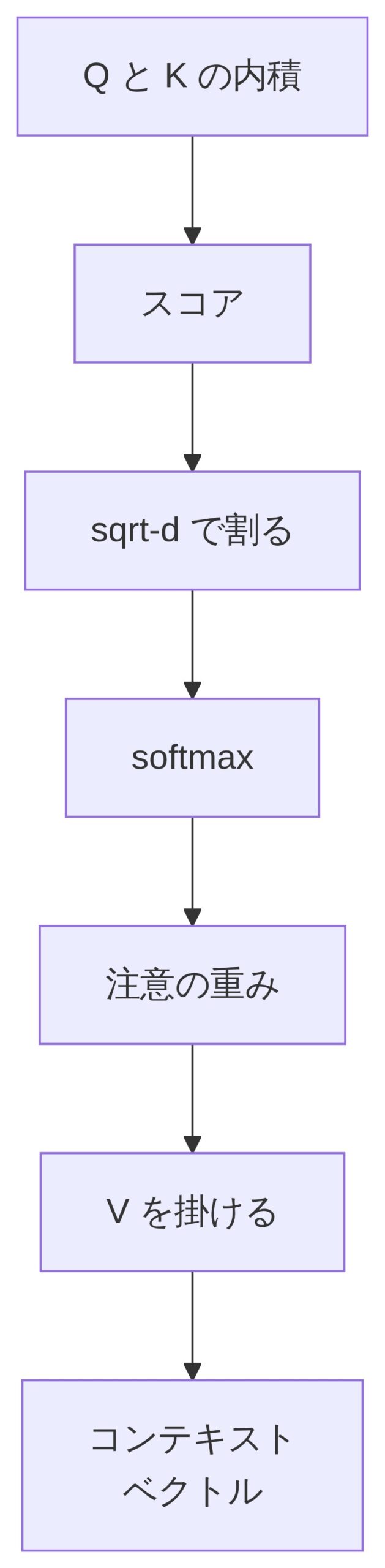
「なんで √d で割るんですか?」
「次元数 d が大きいと内積の値が爆発的に大きくなって、softmax を通したとき1つの値だけが 1 に張り付いてあとは全部ほぼ 0 になってしまう状態(飽和)が起きやすくなる。√d で割って適度なスケールに抑えることで、softmax がちゃんと”なだらかな確率分布”を出せるようにするための保険だ。」
「スケーリングって安全装置みたいな役割なんですね。」
「うまい例えだ、その通り!」
Self-Attention ─ 文の中で単語同士が「会話」する
従来の Attention との違い
「ここまでの Attention はエンコーダ(入力文)とデコーダ(出力文)という2つの異なるソースを橋渡しするものだった。これを Cross-Attention とも呼ぶ。」
「Self-Attention は何が違うんですか?」
「1つの文の内部だけで Q・K・V を全部作る。つまり、文中の単語たちが『お互いにどれだけ関係してるか?』を自分たちだけで計算し合う。まるで単語同士が会話してるイメージだ。」
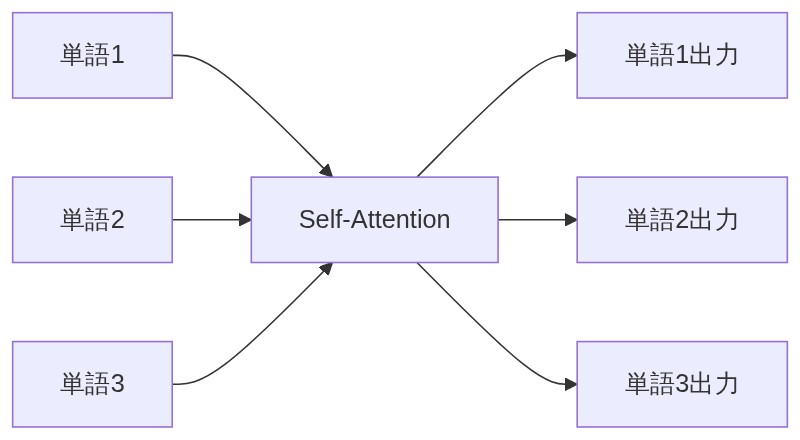
「”The animal didn’t cross the street because it was too tired.” という文で『it が何を指すか』を当てる例で考えてみよう。人間は文脈から “it = animal” だとわかる。Self-Attention を使うと “it” が “animal” に強く注目するスコアを自動で学習できる。離れた位置にある単語の関係を直接つなげられるのが強みだ。」
「RNN だと離れてたら薄まっちゃうけど、Self-Attention なら距離は関係ないんですね。」
「そう!さらに、RNN は前から順番に処理するから並列化できなかった。Self-Attention は全トークンを同時に処理できるから、計算が圧倒的に速い。これも Transformer が強い理由の1つだ。」
Multi-Head Attention ─ 複数の視点で同時に見る
なぜ1回だけでは足りないのか?
「Self-Attention を1回やれば十分じゃないんですか?」
「1つの視点だけだと見落としが出る。たとえば同じ文でも『文法的なつながり(主語・述語の関係)』と『意味的なつながり(同じテーマの単語同士)』は別の話だよな。」
「確かに。構文と意味、両方見たいですね。」
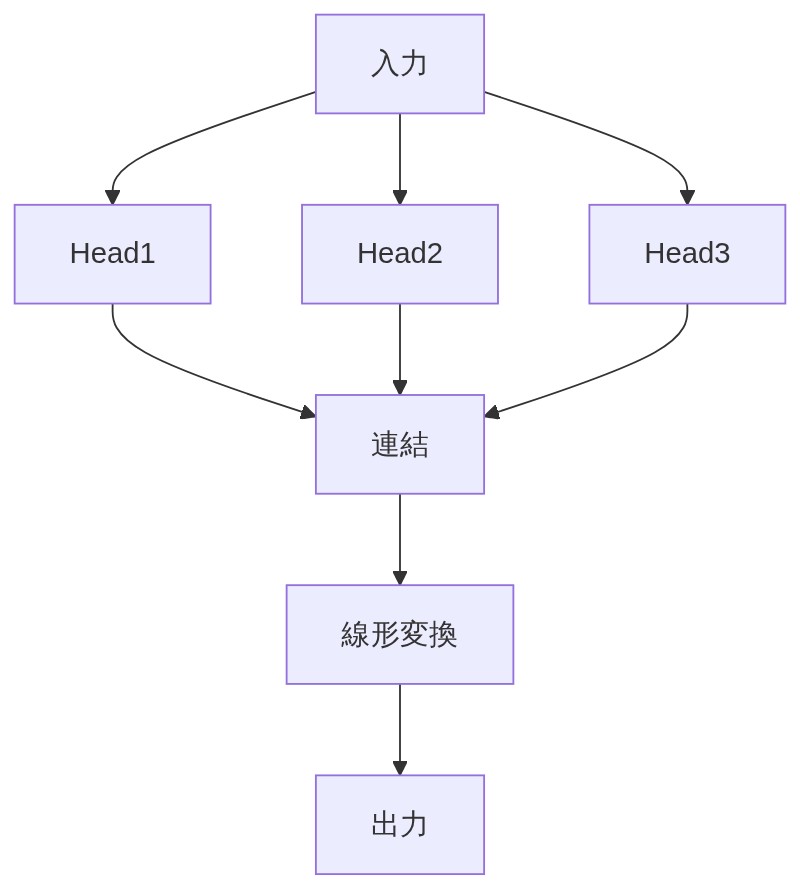
「そこで Multi-Head Attention だ。入力を複数の異なる空間(サブスペース)に変換して、それぞれで独立に Attention を計算する。各ヘッドが異なる種類の関係──構文的・意味的・距離的など──に特化して情報を拾う。」
ヘッドの出力をどう統合するのか?
「各ヘッドが出した答えをどうするんですか?」
「全ヘッドの出力を横に並べて連結(concatenate)して、最後に重み行列をかけて元の次元に変換し、1つの表現にまとめる。原論文では8つのヘッドが使われた。」
「8つの探偵が同時に捜査して、最後に報告をまとめるみたいな感じですね!」
「めちゃくちゃいい例えじゃないか。まさにそれだ。しかも複数ヘッドにすることで、1つのヘッドが間違った方向に過剰に学習するリスクを分散させる効果もある。」
Attention は今どこで活躍しているのか?
Transformer が NLP の標準に
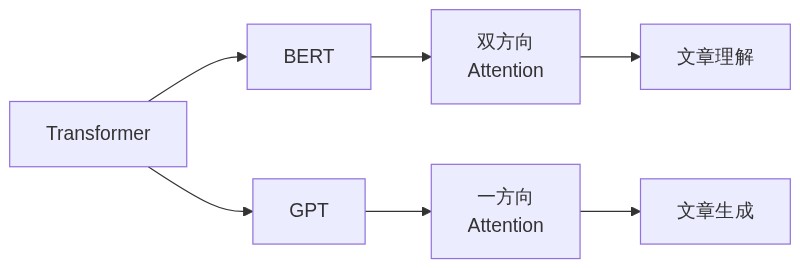
「2017年の『Attention is All You Need』以降、Transformer は自然言語処理の標準的な基盤になった。翻訳精度が大幅に向上しただけじゃなく、2018年には Google が BERT、OpenAI が GPT-1 を発表して大規模言語モデルの時代が幕を開けた。」
「BERT と GPT、よく聞く名前だけど何が違うんですか?」
「Attention の使い方が逆向きなんだ。BERT は文の両方向から Self-Attention を当てて文脈をじっくり理解する設計──質問応答や文章分類に強い。GPT は左から右への一方向Attention で次の単語を予測する設計──文章生成に強い。同じ Attention でも使い方で得意技が変わる。」
「用途に合わせてカスタマイズしてるんですね。」
言語の外にも飛び出した Attention
「翻訳や文章生成だけじゃない。Vision Transformer(ViT) の登場で画像認識にも Attention が広がり、物体検出・セグメンテーション・超解像といったビジョンタスクでも主力モデルになった。」

「画像でも使えるの!?」
「画像をパッチ(小さなブロック)に分割して単語みたいに扱うとうまくいくんだ。さらに VisualBERT や ViLBERT などは画像と言語を同時に処理できるマルチモーダルモデルで、『この画像の中にある猫の気持ちを文章で説明して』みたいなタスクにも対応できる。」
「翻訳から始まって、画像まで!Attention の守備範囲すごい広いんですね。」
「Attention を使えば『どこを見るか』を動的に決められる。それがテキストでも画像でも音声でも応用できる汎用的な強みなんだ。」
まとめ
「じゃあ今日の内容を整理しよう。」
| 概念 | 一言まとめ |
|---|---|
| RNN の限界 | 固定サイズのカバンに全情報を詰め込むため長い文で情報が薄まる |
| Attention の基本 | アライメントスコア → softmax → 重み付き平均でコンテキストベクトルを作る |
| Q / K / V | Q=質問、K=背表紙ラベル、V=本の中身。テーマとラベルの一致度で中身を取り出す |
| Self-Attention | 同じ文の中の単語同士が関係度を計算し合う。並列処理もできる |
| Multi-Head Attention | 複数の視点(ヘッド)で同時に Attention を計算し、結果を統合する |
| 応用範囲 | 翻訳・生成(BERT/GPT)・画像認識(ViT)・マルチモーダルまで幅広い |
「5分で全部わかった気がします!」
「『気がする』から『わかった』にするには、次は実際に Transformer のコードを動かしてみるのが一番の近道だ。比喩で直感を掴んで、コードで体に染み込ませる──これが最強の学習ルートだぞ。」
「次回も教えてください!」
「任せとけ。」
この記事で使ったキーワード早見
Attention/アライメントスコア/softmax/コンテキストベクトル/Query・Key・Value/Scaled Dot-Product Attention/Self-Attention/Multi-Head Attention/Transformer/BERT/GPT/Vision Transformer

コメント