
こんにちは! zhackです!
先日、自然言語処理シリーズの第一弾として、単語ベクトルについて説明いたしました。
今回は単語ベクトルの生成方法として、Skip-Gram Modelについて解説していきます。
また、Skip-Gram Modelについての解説の後、そこから考えられる単語ベクトル生成時の注意事項についても記載しようと思います。
自然言語処理シリーズとして、以下の流れを想定しています。
- 単語ベクトルとは
- 単語ベクトル作成方法
2.1 Skip-Gram Modelの解説(本記事)
2.2 CBOW Modelの解説 - 文ベクトル作成方法
- 文章の意味の把握
- 分かち書き・形態素解析
- 日本語と英語の違い
- 自然言語処理とCNN(未定)
※内容は変動する可能性がございます。
今回は、この第二弾に該当します。
では、いきましょー。
対象読者
今回、対象としている読者は以下のような方です。
- 単語ベクトルが何かわかるけど、どうやって作るのか仕組みを知りたい人
- 単語ベクトル作成の際、気をつけておくべきことを知りたい人
単語ベクトルについて、よくわからない方は以下の記事をご参考ください。

なお、単純に単語ベクトルを作成するプログラムを実装したいという方は、pythonのgensimパッケージを使って関数を呼ぶことで作成することができます。
以下のリンクから使用方法をご確認ください。

また、本記事では以下の文献を参考に解説を進めていきます。
Word2Vec Tutorial – The Skip-Gram Model
Skip Gram Modelとは
Skip Gram Modelは単語ベクトルの作成方法の一つです。
このモデルの作成で行なっていることは、
「ある単語Aを入力したときにその周辺に来るであろう単語を推測するネットワークを作成し、そこから単語Aを表すベクトルを抽出する」
です。
よくわからんぞ!
ですよね 笑
では具体的にどのようなことを行なっているのか解説をしていきます。
Fake Task
参考文献では、先ほどのネットワークを作成する部分をFake Taskと呼んでます。
このネットワークでは、「ある単語を入力したときに、その周辺にある単語を予測する」ということを達成します。
例として、
The quick brown fox jumps over the lazy dog.
の文章を対象に解説します。
また、本記事では「周辺にある単語」を「周辺語」と呼ぶことにします。
ネットワークの作成
着目している単語からどの程度離れた単語までを周辺語と呼ぶかはウィンドウサイズで決定します。
たとえば、ウィンドウサイズが1のとき、
“The”に着目している場合、周辺語は”quick”になります。
”lazy”に着目している場合は、”the”と“dog”です。
着目している単語の前後ウィンドウサイズ分の単語が周辺語になります。
ネットワークの作成に必要な学習データとして、この着目している語と周辺語の組み合わせを学習データとして活用します。
以下の画像は、その学習データをウィンドウサイズが2の場合の学習データになります。
参考文献より引用

上図のような学習データから、周辺語を予測するネットワークを構築します。
つまり、”the”を入力した場合、“quick”が返ってくる、”quick“を入力した場合、”brown”が返ってくるようなネットワークを構築します。
実際にネットワーク構築の際は、この一文だけでなく、大量の文から作成される学習データを使って構築されます。
大量の文章から作成された学習データでネットワークを構築するため、ある単語と推測される周辺語は、ある程度なんらかの関係性があります。
つまり、”eat”に対し”apple”や”orange”は周辺語として出力されるかもしれませんが、”am”や”car”といった単語は出力される可能性は低いでしょう。
しかし、実際PC上でネットワーク作成を行う際、各単語をなんらかの数字で表現する必要があります。
どのように表現するのでしょうか。
one-hotベクトルの利用
PCでネットワークを構築するため、各単語を数値情報に変換する必要があります。
Skip Gram Modelでは、one-hotベクトルという表現方法を使います。
やっていることは非常にシンプルです。
たとえば、先ほど例にした文章の場合、重複なしで8単語存在します。
その場合のone-hotベクトルは以下の図のようになります。
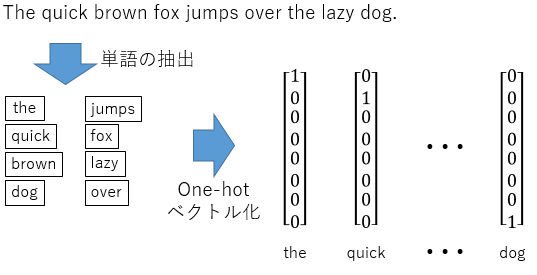
”1“の位置でどの単語か判断するようなベクトルですね。
ベクトルの中で一か所だけ1が入り、その他の値が0であるベクトルになります。
今の例では、全体で8単語でしたので8次元のベクトルで表現することができましたが、実際は大量の文章から学習データを作成するので、何千、何万次元のベクトルになります。
参考文献では、10,000語の単語を学習データに活用しています。
参考文献で構築されているネットワークのモデルは以下のようなモデルになります。
参考文献より引用

10,000語からその周辺語として各単語がどのくらいの可能性で存在するかを、10,000語それぞれについて算出するモデルです。
そのため、入力層および出力層は10,000のニューロンから構成されています。
また、隠れ層には活性化関数がないことが特徴と言えます。
隠れ層に単語ベクトルが!!
さて、Fake Taskに関する解説を行ないました。
実は先程までの手順で単語ベクトルが完成しています。
隠れ層にそのベクトルの数値が格納されています。
入力データから隠れ層に処理が進む過程で、入力データに乗算される重み行列が単語ベクトル群になります。
具体的に、処理の流れを追ってみましょう。
ネットワーク内の処理の流れ
実際にモデルの中でどのように処理が進んでいるのかを図示してみました。

このように、入力されたone-hotベクトルに対し、重み行列Wが乗算され隠れ層に値が入ります。
またその乗算された結果に対し、重み行列W‘が乗算されることで出力層に値が入り、結果が出力されます。
ここで着目してほしいのが、入力されているデータがone-hotベクトルであるということです。
入力データがone-hotベクトルであることで、活性化関数のない隠れ層には、重み行列Wの、ある行が入ります。
下の図に例を挙げます。
参考文献より引用
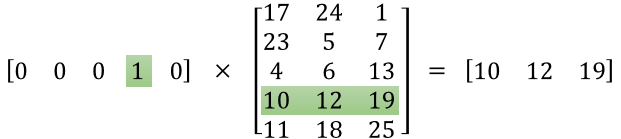
第1項が入力データ、第2項が重み行列Wです。
このように、入力データがone-hotベクトルなので、1が存在する列番号(今回の場合は4列目)と同じ行番号である重み行列の行(4行目)が乗算の解となります。
これは、単語ごとに一意な解となります。
つまり、この解(重み行列Wのある行)をone-hotベクトルの代わりに単語ベクトルとして使用することも可能ということになります。
このようにすることで、one-hotベクトルよりも次元数が少ないベクトルを作成することができました。
このような流れで、周辺語を予測するネットワークに含まれる重み行列から単語ベクトルを作成します。
単語ベクトル生成時に気をつけること
さて、Skip Gram Modelの単語ベクトルを生成するにあたって、調整すべきパラメータ、考えなければならないことについて説明します。
パラメータ
いくつかパラメータは存在しますが、単語ベクトル生成時に調整する主要なパラメータは以下の通りです。
- ウィンドウサイズ
- 単語ベクトルの次元数
ウィンドウサイズ
このウィンドウサイズにより、着目した単語からどれだけ離れたところまでを周辺語と見なすかが決定します。
大きすぎると関係性のない単語まで、周辺語とみなされてしまいます。
たとえば、
I eat an apple every morning in my room.
という文章が学習データだった場合、”eat”に対し“apple”といった食べ物が周辺語として判断されるのは良いと思います。
しかしウィンドウサイズが大きい場合、“room”が周辺語とみなされてしまいます。
こういったあまり関係性の薄い単語が周辺語としてみなされた場合、ノイズとなってしまって生成された単語ベクトルもその単語の性質を表現できていない可能性があります。
適切なウィンドウサイズを見定める必要があります。
単語ベクトルの次元数
参考文献では、10,000の単語に対し300の次元数で表現していました。
このように、次元数(特徴量)の数も調整すべきパラメータの一つになります。
単語数に対して次元数が多いと、単語ベクトルのメリットであるベクトル同士の演算もあまり意味の無さないものになってしまいます。
また少なすぎる場合も、表現できる特徴量が少なくなり、単語ごとの意味のバリエーションの表現が難しくなります。
考えるべきこと
学習データを生成する文章群
学習データを生成する文章群として、どのような文章群を用意するかは考慮すべきことです。
同じ単語だったとしても、分野や領域によって意味は異なることがあるためです。
「どのような語が周辺語であるか」という情報をもとに単語ベクトルを生成するので、同一の単語で使われ方が異なる文章から学習データを作成するとノイズとなってしまいます。
このため、どのような文章から学習データを生成するかということは考えなければいけません。
さいごに
長くなってしまいましたが、以上が単語ベクトル生成アルゴリズムの一つ、Skip Gram Modelの解説でした。
実際はPythonのプログラムの関数を実行するだけでできてしまうんですがね、、
理解の助けになればと思います。
ではでは!


コメント
[…] 2.1 Skip-Gram Modelの解説 2.2 CBOW […]
[…] 2.1 Skip-Gram Modelの解説 2.2 CBOW […]